

Le domaine du Machine Learning regorge d’algorithmes pour répondre à différents besoins. Chacun a ses spécificités mathématiques et algorithmiques. Pour quelqu’un qui débute dans le domaine, cela peut ne pas être évident à appréhender. J’ai compilé cette liste regroupant 9 algorithmes de Machine Learning les plus basiques mais redoutables pour mieux vous retrouver dans cette foire aux algos !
Note : J’ai préféré garder le nom anglais de ces algorithmes pour ne pas vous embrouiller avec des traductions « hasardeuses » 🙂
1. Linear Regression
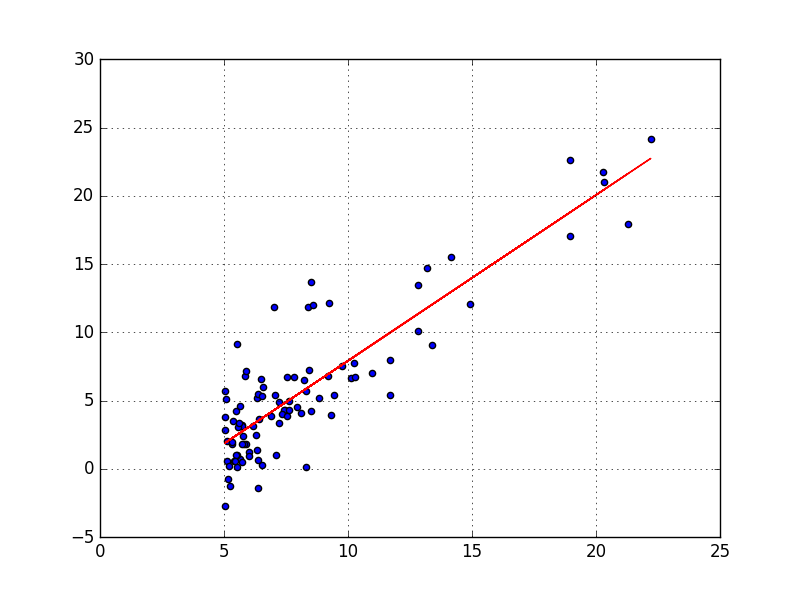
Les algorithmes de régression linéaire modélisent la relation entre des variables prédictives et une variable cible. La relation est modélisée par une fonction mathématique de prédiction. Le cas le plus simple est la régression linéaire univariée. Elle va trouver une fonction sous forme de droite pour estimer la relation. La régression linéaire multivariée intervient quand plusieurs variables explicatives interviennent dans la fonction de prédiction. Et finalement, la régression polynomiale permet de modéliser des relations complexes qui ne sont pas forcément linéaires.
2. Logistic Regression
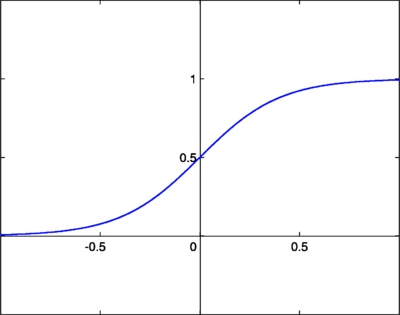
La régression logistique est une méthode statistique pour effectuer des classifications binaires. Elle prend en entrée des variables prédictives qualitatives et/ou ordinales et mesure la probabilité de la valeur de sortie en utilisant la fonction sigmoïd (représentée dans la photo).
On peut effectuer la classification multi-classes (par exemple classifier une photo en trois possibilités comme moto, voiture, tramway). En utilisant la régression logistique et la méthode un-contre-tous (One-Versus-All classification).
La régression logistique permettra de répondre à des problèmes comme :
- Est-ce que le client est solvable pour lui accorder un crédit ?
- Est-ce que la tumeur diagnostiquée est bénigne ou maline ?
3. Support Vector Machine (SVM)
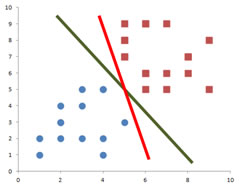
Machine à Vecteurs de Support (SVM) est lui aussi un algorithme de classification binaire. Tout comme la régression logistique. Si on prend l’image ci-dessus, nous avons deux classes (Imaginons qu’il s’agit de e-mails, et que les mails Spam sont en rouge et les non spam sont en bleu). La régression Logistique pourra séparer ces deux classes en définissant le trait en rouge. le SVM va opter à séparer les deux classes par le trait vert.
Sans entrer dans les détails, et pour des considérations mathématiques, le SVM choisira la séparation la plus nette possible entre les deux classes (comme le trait vert). C’est pour cela qu’on le nomme aussi Large Margins classifier (classifieur aux marges larges).
4. Naïve Bayes
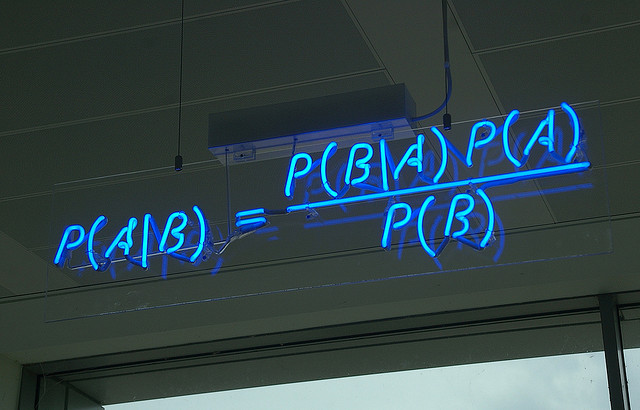
Naïve Bayes est un classifieur assez intuitif à comprendre. Il se base sur le théorème de Bayes des probabilités conditionnelles. L’image ci-dessus est la formule du théorème de Bayes.
Naïve Bayes assume une hypothèse forte (naïve). En effet, il suppose que les variables sont indépendantes entre elles. Cela permet de simplifier le calcul des probabilités.
Généralement, le Naïve Bayes est utilisé pour les classifications de texte (en se basant sur le nombre d’occurrences de mots).
5. Anomaly Detection

Anomaly Detection est un algorithme de Machine Learning pour détecter des patterns anormaux. Imaginez par exemple que vous receviez dans votre compte en banque 2000€ mensuellement et que un jour vous déposiez 10 000€ d’un coup. L’algorithme détectera cela comme une anomalie.
Cet algorithme est très utile pour la détection de fraudes dans les transactions bancaires, et les détections d’intrusions.
6. Decision Trees
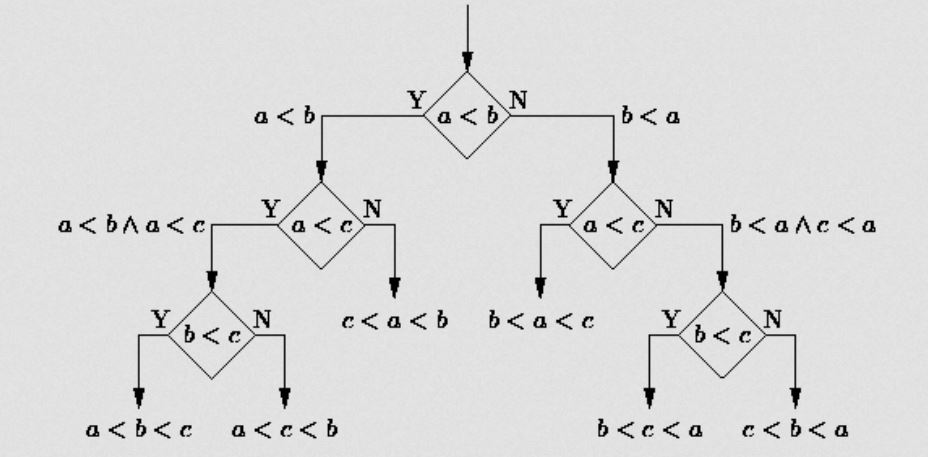
L’arbre de décision est un algorithme qui se base sur un modèle de graphe (les arbres) pour définir la décision finale. Chaque nœud comporte une condition, et les branchements sont en fonction de cette condition (Vrai ou Faux). Plus on descend dans l’arbre, plus on cumule les conditions. L’image ci-dessus illustre ce fonctionnement.
7. Neurals Networks
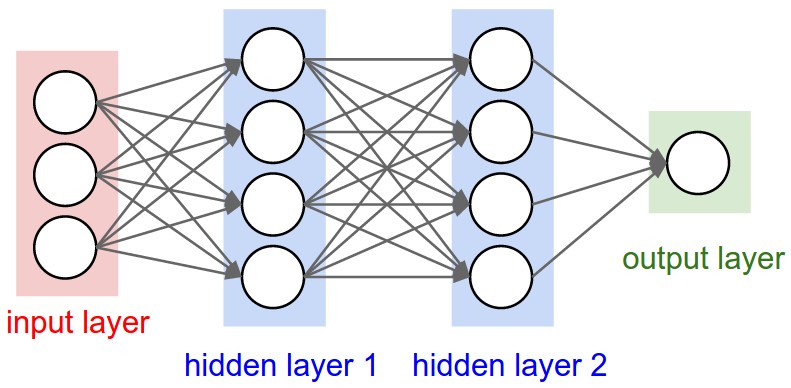
Les réseaux de neurones sont inspirés des neurones du système nerveux humains. Ils permettent de trouver des patterns complexes dans les données. Ces réseaux de neurones apprennent une tâche spécifique en fonction des données d’entrainement.
Les réseaux de neurones se composent de nœuds (les cercles dans l’image). Dans ces réseaux, on retrouve le tiers d’entrée (Input Layer) qui va recevoir les données d’entrées. L’Input Layer va propager les données par la suite aux tiers cachés (Hidden Layers). Finalement le Tiers de sortie (le plus à droite) permet de produire le résultat de classification. Chaque tiers du réseau de neurones est un ensemble d’interconnexions des noeuds d’un tiers avec ceux des autres tiers.
8. K-Means
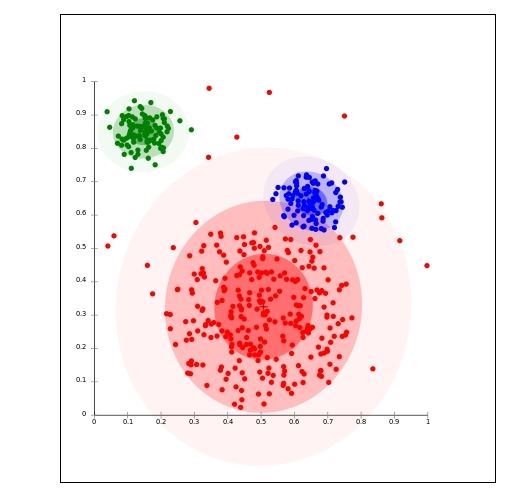
Imaginez que vous souhaitiez lancer une campagne publicitaire et que vous vouliez envoyer un message publicitaire différent en fonction du public visé. Vous devez dans un premier lieu regrouper la population ciblée sous forme de groupes. Les individus de chaque groupe auront un degré de similarité (age, salaire etc…)
C’est ce que fera l’algorithme K-Means !
K-Means est un algorithme de clustering en Unsupervised Learning. On lui donne un ensemble d’éléments (des données), et un nombre de groupes K. K-means va segmenter en K groupes les éléments. Le groupement s’effectue en minimisant la distance euclidienne entre le centre du cluster et un élément donné.
9. Gradient Descent
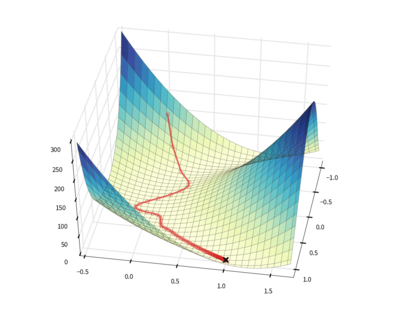
Vu son importance, j’inclus l’algorithme Gradient Descent dans cette liste bien qu’il ne soit pas « vraiment » un algorithme de machine Learning. En effet, Gradient Descent est un algorithme itératif de minimisation de fonction de coût. cette minimisation servira à produire des modèles prédictifs comme la régression logistique et la régression linéaire. Pour plus d’informations sur cet algorithme, vous pouvez lire cet article expliquant son fonctionnement.
Ping : Data scientist : faites grimper votre salaire en 2020 • HIDDEN MARKET