
K-means (k-moyennes) est un algorithme non supervisé de clustering, populaire en Machine Learning. Lors de cet article, nous allons détailler son fonctionnement et dans quel cas d’usage il peut être appliqué.

Qu’est ce que le clustering
Le clustering est une méthode d’apprentissage non supervisé (unsupervised learning). Ainsi, on n’essaie pas d’apprendre une relation de corrélation entre un ensemble de features  d’une observation et une valeur à prédire
d’une observation et une valeur à prédire  , comme c’est le cas pour l’apprentissage supervisé. L’apprentissage non supervisé va plutôt trouver des patterns dans les données. Notamment, en regroupant les choses qui se ressemblent.
, comme c’est le cas pour l’apprentissage supervisé. L’apprentissage non supervisé va plutôt trouver des patterns dans les données. Notamment, en regroupant les choses qui se ressemblent.
En apprentissage non supervisé, les données sont représentées comme suit :

Chaque ligne représente un individu (une observation). A l’issu de l’application du clustering, on retrouvera ces données regroupées par ressemblance. Le clustering va regrouper en plusieurs familles (clusters) les individus/objets en fonction de leurs caractéristiques. Ainsi, les individus se trouvant dans un même cluster sont similaires et les données se trouvant dans un autre cluster ne le sont pas.
Il existe deux types de clustering :
- Le clustering hiérarchique
- Le clustering non-hiérarchique (partitionnement)
J’élaborerai la différence entre ces deux concepts lors d’un autre article. Pour le moment, retenez juste, que le concept de clustering tel que je l’ai décrit lors de ce paragraphe est un clustering non hiérarchique.
Qu’est ce que K-means
K-means est un algorithme non supervisé de clustering non hiérarchique. Il permet de regrouper en  clusters distincts les observations du data set. Ainsi les données similaires se retrouveront dans un même cluster. Par ailleurs, une observation ne peut se retrouver que dans un cluster à la fois (exclusivité d’appartenance). Une même observation, ne pourra donc, appartenir à deux clusters différents.
clusters distincts les observations du data set. Ainsi les données similaires se retrouveront dans un même cluster. Par ailleurs, une observation ne peut se retrouver que dans un cluster à la fois (exclusivité d’appartenance). Une même observation, ne pourra donc, appartenir à deux clusters différents.
Notion de similarité
Pour pouvoir regrouper un jeu de données en cluster distincts, l’algorithme K-Means a besoin d’un moyen de comparer le degré de similarité entre les différentes observations. Ainsi, deux données qui se ressemblent, auront une distance de dissimilarité réduite, alors que deux objets différents auront une distance de séparation plus grande.
Les littératures mathématiques et statistiques regorgent de définitions de distance, les plus connues pour les cas de clustering sont :
- La distance Euclidienne : C’est la distance géométrique qu’on apprend au collège. Soit une matrice à
 variables quantitatives. Dans l’espace vectoriel
variables quantitatives. Dans l’espace vectoriel  . La distance euclidienne
. La distance euclidienne  entre deux observations
entre deux observations  et
et  se calcule comme suit :
se calcule comme suit :

- La distance de Manhattan (taxi-distance) : est la distance entre deux points parcourue par un taxi lorsqu’il se déplace dans une ville où les rues sont agencées selon un réseau ou un quadrillage. Un taxi-chemin est le trajet fait par un taxi lorsqu’il se déplace d’un nœud du réseau à un autre en utilisant les déplacements horizontaux et verticaux du réseau. (source wikipedia.)
Choisir K : le nombre de clusters
Choisir un nombre de cluster K n’est pas forcément intuitif. Spécialement quand le jeu de données est grand et qu’on n’ait pas un a priori ou des hypothèses sur les données. Un nombre grand peut conduire à un partitionnement trop fragmenté des données. Ce qui empêchera de découvrir des patterns intéressants dans les données. Par contre, un nombre de clusters trop petit, conduira à avoir, potentiellement, des cluster trop généralistes contenant beaucoup de données. Dans ce cas, on n’aura pas de patterns « fins » à découvrir.
Pour un même jeu de données, il n’existe pas un unique clustering possible. La difficulté résidera donc à choisir un nombre de cluster qui permettra de mettre en lumière des patterns intéressants entre les données. Malheureusement il n’existe pas de procédé automatisé pour trouver le bon nombre de clusters.
La méthode la plus usuelle pour choisir le nombre de clusters est de lancer K-Means avec différentes valeurs de et de calculer la variance des différents clusters. La variance est la somme des distances entre chaque centroid d’un cluster et les différentes observations inclues dans le même cluster. Ainsi, on cherche à trouver un nombre de clusters de telle sorte que les clusters retenus minimisent la distance entre leurs centres (centroids) et les observations dans le même cluster. On parle de minimisation de la distance intra-classe.
La variance des clusters se calcule comme suit :

Avec :
 : Le centre du cluster (le centroïd)
: Le centre du cluster (le centroïd) : la ième observation dans le cluster ayant pour centroïd
: la ième observation dans le cluster ayant pour centroïd  : La distance (euclidienne ou autre) entre le centre du cluster et le point
: La distance (euclidienne ou autre) entre le centre du cluster et le point
Généralement, en mettant dans un graphique les différents nombres de clusters en fonction de la variance, on retrouve un graphique similaire à celui-ci :
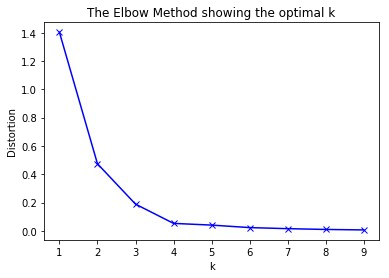 On remarque sur ce graphique, la forme d’un bras où le point le plus haut représente l’épaule et le point où vaut 9 représente l’autre extrémité : la main. Le nombre optimal de clusters est le point représentant le coude. Ici le coude peut être représenté par valant 2 ou 3. C’est le nombre optimal de clusters. Généralement, le point du coude est celui du nombre de clusters à partir duquel la variance ne se réduit plus significativement. En effet, la « chute » de la courbe de variance (distortion) entre 1 et 3 clusters est significativement plus grande que celle entre 5 clusters et 9 clusters.
On remarque sur ce graphique, la forme d’un bras où le point le plus haut représente l’épaule et le point où vaut 9 représente l’autre extrémité : la main. Le nombre optimal de clusters est le point représentant le coude. Ici le coude peut être représenté par valant 2 ou 3. C’est le nombre optimal de clusters. Généralement, le point du coude est celui du nombre de clusters à partir duquel la variance ne se réduit plus significativement. En effet, la « chute » de la courbe de variance (distortion) entre 1 et 3 clusters est significativement plus grande que celle entre 5 clusters et 9 clusters.
Le fait de chercher le point représentant le coude, a donné nom à cette méthode : La méthode Elbow (coude en anglais).
Finalement, le choix (au vu de ce graphique), entre 2 ou 3 clusters, reste un peu flou et à votre discrétion. Le choix se fera en fonction de votre jeu de données et ce que vous cherchez à accomplir. Finalement, Il n’y a pas de solution unique à un problème de clustering.
Cas d’utilisation K-means
K-Means en particulier et les algorithmes de clustering de façon générale ont tous un objectif commun : Regrouper des éléments similaires dans des clusters. Ces éléments peuvent être tous et n’importe quoi, du moment qu’ils sont encodés dans une matrice de données.
Les champs d’application de K-Means sont nombreux, il est notamment utilisé en :
- la segmentation de la clientèle en fonction d’un certain critère (démographique, habitude d’achat etc….)
- Utilisation du clustering en Data Mining lors de l’exploration de données pour déceler des individus similaires. Généralement, une fois ces populations détectées, d’autres techniques peuvent être employées en fonction du besoin.
- Clustering de documents (regroupement de documents en fonction de leurs contenus. Pensez à comment Google Actualités regroupe des documents par thématiques.)
Fonctionnement de l’algorithme K-Means
k-means est un algorithme itératif qui minimise la somme des distances entre chaque individu et le centroïd. Le choix initial des centroïdes conditionne le résultat final.
Admettant un nuage d’un ensemble de points, K-Means change les points de chaque cluster jusqu’à ce que la somme ne puisse plus diminuer. Le résultat est un ensemble de clusters compacts et clairement séparés, sous réserve de choisir la bonne valeur du nombre de clusters .
Principe algorithmique
Algorithme K-means
Entrée :
- K le nombre de cluster à former
- Le Training Set (matrice de données)
DEBUT
Choisir aléatoirement K points (une ligne de la matrice de données). Ces points sont les centres des clusters (nommé centroïd).
REPETER
Affecter chaque point (élément de la matrice de donnée) au groupe dont il est le plus proche au son centre
Recalculer le centre de chaque cluster et modifier le centroide
JUSQU‘A CONVERGENCE
OU (stabilisation de l’inertie totale de la population)
FIN ALGORITHME
Note 1: Lors de la définition de l’algorithme, quand je parle de « point », c’est un point au sens « donnée/data » qui se trouve dans un espace vectoriel de dimension . Avec : le nombre de colonnes de la matrice de données.
Note 2 : La convergence de l’algorithme K-Means peut être l’une des conditions suivantes :
- Un nombre d’itérations fixé à l’avance, dans ce cas, K-means effectuera les itérations et s’arrêtera peu importe la forme de clusters composés.
- Stabilisation des centres de clusters (les centroids ne bougent plus lors des itérations).
L’affectation d’un point  à un cluster se fait en fonction de la distance de ce point par rapport aux différents centroides. Par ailleurs, ce point se fera affecté à un cluster
à un cluster se fait en fonction de la distance de ce point par rapport aux différents centroides. Par ailleurs, ce point se fera affecté à un cluster  s’il est plus proche de son centroid (distance minimale). Finalement, la distance entre deux points dans le cas de K-Means se calcule par les méthodes évoquées dans le paragraphe « notion de similarité ».
s’il est plus proche de son centroid (distance minimale). Finalement, la distance entre deux points dans le cas de K-Means se calcule par les méthodes évoquées dans le paragraphe « notion de similarité ».
Remarques sur le K-Means
Optimums locaux
En analysant la façon de procéder de l’algorithme de K-means, on remarque que pour un même jeu de données, on peut avoir des partitionnements différents. En effet, L’initialisation des tous premiers centroids est complétement aléatoire. Par conséquent l’algorithme trouvera des clusters différents en fonction de cette première initialisation aléatoire. De ce fait, la configuration des clusters trouvés par K-Means peut ne pas être la plus optimale. On parle d’optimum local.
Afin de palier aux problèmes des optimums locaux, il suffit de lancer K-means plusieurs fois sur le jeu de données (avec le même nombre de clusters et des initialisations initiales des centroids différentes) et voir la composition des clusters qui se forment. Par la suite garder celui qui convient à votre besoin.
Résumé
Dans cet article, vous avez découvert le principe de fonctionnement de K-Means. Il s’agit d’un algorithme d’apprentissage non supervisé dédié au clustering non hiérarchique.
Vous connaissez maintenant :
- Ce que c’est l’algorithme K-Means
- Les cas où vous pouvez utiliser K-Means
- Comment fonctionne cet algotithme ainsi que ses forces et ses limitations.
Finalement , j’espère que cet article pourra vous aider ,si vous avez des questions n’hésitez pas à me les poser par commentaire. J’y répondrai du mieux que je peux. 🙂
Limpide. Bravo et merci
Merci Mehdi 🙂
Merci pour cet article très pédagogique. Pour rebondir sur une question posée récemment dans cross validated, comment gérer vous les contraintes « pragmatiques » (économiques, techniques) dans le choix du nombre de clusters.
https://stats.stackexchange.com/questions/338980/choosing-the-number-of-clusters-clustering-validation-criterions-vs-domain-the
J’imagine que parfois, les contraintes techniques disent « le nombre de cluster devra être égal à 3 » ou « devra être compris entre 3 et 5 ». Dans ce cas là, y a t-il des vérifs à faire pour savoir si cela n’est pas trop aberrant ?
La qualité de vos clusters est forcément liée à la nature des données que vous manipulez.
Généralement, la méthode Elbow ne sert qu’à titre indicatif pour nous aider à réduire l’intervalle des possibilité du nombre de clusters K. Il ne s’agit pas d’une technique infaillible.
Le plus approprié serait, notamment, de changer les valeurs de K progressivement et voir quels clusters émergent. Quand la composition des clusters ne changent plus significativement, c’est qu’on a des clusters assez « stables ».
Vous pourrez également, apprécier la pertinence de vos clusters en utilisant la méthode « silouhette » : https://en.wikipedia.org/wiki/Silhouette_(clustering)
Super résumé,
Un grand merci j ai tout compris et c’était pas gagné 😉
C’est trop cool. Vous êtes très fort ! top classe votre pédagogie.
Merci.
Merci Lionel ton commentaire l’est tout au temps ! 🙂
Bonjour younes ! Je ne suis qu’un débutant je suis en Master de mathématiques appliquées et j’ai eu à faire le cours de Python pour la datascience . J’ai un exos et je veux que tu m’aides à comprendre leS différentes méthodes de clustering supervisé ou pas . Merci younes in advance 🙂
Bonjour Younes et bravo pour votre article c’est limpide, y compris pour un profane comme moi qui débute totalement en la matière.
J’aurais 2 questions si vous le permettez mais je dois d’abord poser le contexte.
A savoir : ma matrice d’entrée contient +-80 colonnes et 100.000 lignes.
J’ai « hérité » (de consultants externes que je n’ai même pas croisé soit ce n’est pas l’essentiel mais juste pour vous dire que je ne dispose d’aucune doc et/ou info quelconque sur la méthode qu’ils ont appliquées) d’un code Python qui permet de générer le k-means en voici les 3 phrases clés :
N_CLUSTERS = 7
from sklearn import cluster
kmeans = cluster.KMeans(n_clusters=N_CLUSTERS, random_state=0).fit(Z)
En sortie j’obtiens en effet une seconde matrice composée d’une liste de « features » (arguments ou « caractéristiques »..) et de 7 colonnes correspondants au 7 clusters avec les valeurs correspondantes de ces « features ». Il s’agit bien entendu des fameux « centroids » dont vous parlez.
Première observation : alors que j’avais 80 features (colonnes) en entrées il ne m’en reste que 75 en sortie, j’ai pu déterminer que c’était du au fait que 5 d’entres eux ne présentait jamais aucune « variance » j’en déduis que l’algo les a lui même éliminé puisqu’il ne permettait en aucune façon de distinguer les clusters entre eux.
Donc à présent je me retrouve avec ces 75 arguments et 7 « vecteurs » de valeur correspondante (normalisée et non normalisée d’ailleurs çàd « brut » donc présentant potentiellement de grand écart de valeurs absolue entre feature et « ramené sur une échelle similaire » via ce qu’il appel des « Z-score » que vous connaisser probablement).
Voici enfin ma première question : comment choisir parmi ces 75 « mesures/caractéristiques » celle qui vont définir au mieux le Cluster 1, le Cluster 2, … Cluster 7 ?
Ce que mes fameux consultants ont fait puisque je dispose par ailleur d’un splendide « PowerPoint » de leur part (vous connaissez les consultants) qui synthétise leur magnifique travail ( 🙂 ) et qui explique en 1 slide qu’en réalité seul 4 clusters finalement peuvent être retenu et que le cluster 1 peut être décrit comme suit : « … » (3 ou 4 phrase) car feature[7] = 18,1 feature [12] = 42,7 featute[56] = 12,3 (idem avec 3 autres clusters).
Comment ont ils bien pu passer de la matrice 75 x 7 à cette synthèse « simplfiiée » ? Mystère.
2ième et plus anecdotique question : j’ai déjà fait retourner au moins 10x l’algo sans changer quoi que ce soit et il me ressort systèmatiquement les mêmes centroid à la virgule près, comment est ce possible sachant que la méthode que vous décrivez si bien prévoit que « l’init load » (choix arbitraire des centroids de départs » est aléatoire ! ???
Désolé d’avoir été si long et merci d’avance pour votre réponse.
Bien à vous
Xavier
Bonjour Xavier,
La réponse est envoyée en MP (mail).
Merci
bonsoir younes,
j’ai mon collègue qui lui aussi à hériter d’un cas similaire dans une entreprise. et qui m’a contacter pour plus d’aide. Mais comme je ne comprends pas non plus « son héritage » . j’ai fais un tour sur mon biblio perso ( Mrmint.fr : Svp c’est entre nous ici ).
je suis très intéressé par votre solution.
merci beaucoup
Bonjour,
Je me demande pourquoi parfois le nombre de clusters final est inférieur aux nombres de centroïdes que l’on a initialisé.
En espérant que vous puissiez me répondre,
Respectueusement
Emeline
Bonjour Emeline,
Je n’arrive pas à voir comment vous pouvez obtenir avec K-Means un nombre de clusters inférieur à celui des centroids.
Comment vous êtes arrivée à ce cas de figure ?
Merci
Ping : Tout pour bien démarrer dans l’intelligence artificielle (Partie 4) – Deep Learning - Pensée Artificielle
Merci younes pour tout vos efforts
avec plaisir 🙂
Bonjour, Je vous remercie pour ces explications on ne peut plus claires !!!! 😀 Auriez vous des références biblio à recommander pour en apprendre davantage sur cette fonction ?
Bonjour Floriane,
Merci pour ton commentaire 🙂
Je vous conseille la video de cours d’Andrew NG : https://www.youtube.com/watch?v=hDmNF9JG3lo
Je vous conseille aussi ce cours universitaire de l’université de Lyon qui parle de variantes de k-means :
http://eric.univ-lyon2.fr/~ricco/cours/slides/classif_centres_mobiles.pdf
Bonjour Younes
Merci beaucoup pour cette explication .
Vous pouvez comment on peut choisir le Nombre K, en se basant à quoi?
Est- ce que vous avez un exemple d’applications sous R pou mieux comprendre.??
Merci
Bonjour Laila,
Le nombre K peut être choisi selon deux méthodes :
La méthode Elbow : https://en.wikipedia.org/wiki/Elbow_method_(clustering)#:~:text=In%20cluster%20analysis%2C%20the%20elbow,number%20of%20clusters%20to%20use.
La méthode Silouhette : https://fr.wikipedia.org/wiki/Silhouette_(clustering)
Chacune des méthodes à ses avantages et ses limites, je vous ai mis deux liens décrivant ces méthodes.
Quant à R, personnellement je n’en fais pas, du coup je ne suis pas le mieux placer pour vous conseiller sur ce Langage. Toutefois, la méthodologie de travail reste la même que ce soit python ou R.
Bon courage
Younes
Bravo c’est très pédagogique. Merci
Bonjour,
Article très intéressant et pédagogique ! Merci beaucoup.
(Petite erreur sur la formule de la distance Euclidienne : dans la somme c’est (x1j – x2j)² et non (x1n – x2n)²
Bonjour, Je vous remercie pour ces explications monsieur Younes.
S’il vous plait, est ce que vous pouvez me proposer une problématique qui persiste encore sur l’algorithme k-means,
pour que je puisse la traité, se forme d’un article !!
J’ai besoin d’aide svp.
merci d’avance.
Bonjour Driss,
Merci tout d’abord pour votre commentaire !
Je ne suis pas sur d’avoir compris votre question. Si vous cherchez un jeu de données pour vous entrainer, je vous propose de faire un tour sur les jeux de données de Kaggle ou encore ce site qui regorge de jeux de données: https://archive.ics.uci.edu/ml/index.php
Bon courage
Younes
Un grand merci pour cet article! Excellent
Bonjour
Excellent article.
Pourquoi vous n’appuyez pas l’article par un exemple pratique qui ne serait pas ambiguë et qui couvrira toute la théorie qu’on a vu
Bonjour à vous, merci pour le magnifique travail que vous abattez.
J’ai à peu près la même préoccupation que Xavier.
Je vous remercierai de me faire également parvenir la réponse que vous lui aviez envoyer par mail