
Dans cet article, j’ai évoqué la méthodologie générale pour aborder un problème de Machine Learning. Cette méthode de travail est constituée de 5 étapes. J’ai parlé des deux premières étapes lors de mon précédent article. On parlera maintenant des trois étapes restantes.
Pour rappel la méthodologie de travail comportait ces 5 étapes :
- Définition du problème
- Préparation des données
- Choix du bon algorithme
- Optimisation des résultats
- Présentation des résultats finaux
Choix du bon algorithme
Plusieurs types de problèmes sont résolus par le machine learning. Notamment la classification, la régression et le clustering. A chaque type de problème, on peut avoir plusieurs algorithmes candidats pour le résoudre. Les facteurs qui peuvent entrer en jeu pour choisir le bon algorithme peuvent être nombreux, notamment le nombre de caractéristiques (features), la quantité de données qu’on a…etc.
Voici un schéma permettant de vous aiguiller dans le choix de votre algorithme.
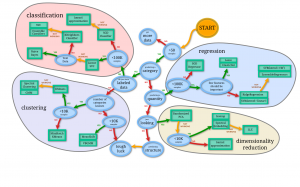
Optimisation des résultats
Après avoir déroulé son algorithme sur ses données d’entraînement (Training set) et faire des prédictions avec le jeu de test (Test Set), il est temps d’évaluer la performance de notre algorithme.
En effet, le fait que notre algorithme effectue des bonnes prédictions n’est pas forcément un bon signe. Il se peut que notre modèle souffre du phénomène de sur-apprentissage (overfitting). Dans ce cas, ce dernier pourra mal prédire des situations nouvelles qu’il n’a pas vu auparavant dans sa phase d’apprentissage.
Dans l’autre sens, si l’algorithme prédit des valeurs sans rapport avec la réalité, il se peut que ce dernier souffre de sous-apprentissage (underfitting).
L’optimisation des résultats revient à affiner le modèle de prédiction pour qu’il puisse se généraliser sur des données non encore vues par l’algorithme lors de sa phase d’apprentissage
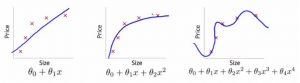
Diverses fonctions de prédiction du prix d’une maison en fonction de sa taille
L’image la plus à droite pourrait nous faire croire qu’on ait obtenu un bon modèle de prédiction. Toutefois, dans ce cas de figure, on est face au phénomène de sur-apprentissage (overfitting). Il prédira mal le prix d’une maison qu’il n’a pas encore vu lors de sa phase d’apprentissage
L’image la plus à gauche montre une fonction de prédiction sous forme d’une droite:  . En d’autres termes on fait une supposition forte que le prix d’une maison est corrélé linéairement avec la taille de maison. Nos données (les croix en rouge) montrent que ce n’est pas forcément le cas. On dit que ce modèle a un fort biais (High Biais) et souffre de Underfitting.
. En d’autres termes on fait une supposition forte que le prix d’une maison est corrélé linéairement avec la taille de maison. Nos données (les croix en rouge) montrent que ce n’est pas forcément le cas. On dit que ce modèle a un fort biais (High Biais) et souffre de Underfitting.
L’image du centre, montre une fonction polynomiale du second degrés qui concorde bien nos données. Ce modèle est bien adapté pour prédire le prix d’une nouvelle maison.
Présentation des résultats finaux
Les résultats d’un problème de Machine Learning sont souvent complexes à interpréter. Les présenter aux parties prenantes du projet sans en donner une interprétation simple de leur signification ne sera pas d’une grande utilité pour eux.
Présenter les résultats d’un problème de Machine Learning peut prendre plusieurs formes : faire un document rapport détaillant et interprétant les résultats, faire une présentation Power Point®, voire faire une démonstration en directe.
Quelque soit le format choisi pour présenter les résultats, il convient de répondre aux points suivants :
- Le contexte : Soulever le contexte de la problématique et les motivations de sa résolution
- Le problème : Décrire de façon concise le problème qu’on cherche à résoudre.
- La solution : Décrire la solution apportée en terme d’architecture, moyen d’exploitation de la solution etc…
- Limitations : Si la solution n’est pas universelle ou comporte des limitations, il vaut mieux les lister. Cela donne une crédibilité à votre solution et peut ouvrir des voies vers de nouveaux axes d’amélioration.
- Conclusion : Revisiter d’une façon rapide la description du problème ainsi que de la solution et les bénéfices tirées de cette dernière.
Résumé
Durant ces deux articles, vous avez vu les grandes lignes pour aborder un problème complexe de Machine Learning. Même si ne faites qu’apprendre un nouvel algorithme, prenez le temps de suivre la démarche pour vous y habituer et adopter les bons réflexes.
Finalement, je suis conscient que j’ai survolé quelques notions notamment le overfitting et l’underfitting, et comment évaluer les performances d’un algorithme. Toutes ces notions feront l’objet d’articles plus détaillés dans le futur.
N’hésitez pas à laisser un commentaire pour donner votre avis sur la méthodologie, et si l’article vous plait, n’oubliez pas de le partager 😉
Merci beaucoup pour ces 2 articles Partie 1 et Partie 2, ça éclaircie nettement la méthode à adopter pour résoudre un problème.
J’aurais aimée avoir plus d’exemples par rapport au choix de l’algorithme. Le schéma est très bien et guide vers un choix mais avec des exemples réels il sera surement plus utile.
Peut être que vous l’avez fait dans un autre article, dans ce cas pouvez vous m’indiquer lequel.
Et merci encore pour toutes ces précisions.
Bonjour Thouraya,
Quand on cherche à faire un modèle prédictif, on ne connait pas forcément la relation/fonction qui lie des observations à un résultat. On est donc dans un mode « experimentations » et heuristique.
Dans ce sens, souvent, le plus judicieux est d’essayer plusieurs algorithmes sur le même problème et retenir celui qui produit le meilleur modèle. Le choix du modèle doit se faire en fonction d’une métrique de score pour comparer objectivement les différents modèles obtenus.
Bonne journée
Salut, Merci beaucoup pour les 2 parties c’est très intéressant ça m’a aidé de comprendre l’intérêt d’etablir les étapes sur lesquelles on doit passer pour résoudre n’importe quel problème notamment celui du ml