

Pré-requis
Pour suivre ce tutoriel, vous devez disposer sur votre ordinateur, des éléments suivants :
- le SDK Python 3
- Un environnement de développement Python. Jupyter notebook (application web utilisée pour programmer en Python) fera bien l’affaire
- Disposer de la bibliothèque Sickit-Learn.
Vous pouvez installer tous ces pré-requis en utilisant Anaconda, une distribution Python bien connue. Je vous invite à lire mon article sur Anaconda pour installer cette dernière.
Jeu de données utilisé
La donnée est le nerf de la guerre quand il s’agit de Machine Learning. Pour ce tutoriel, on utilisera le célèbre jeu de données MNIST. Ce dernier est une base de donnée de chiffres manuscrits très utilisée en Machine Learning, notamment pour l’entrainement et le test de modèles prédictifs. Wikipedia fournit des informations abondantes sur ce dataset.

Représentation des données
 .
. chiffres que nous diviserons par la suite en deux sous ensembles : d’entrainement et de test.
chiffres que nous diviserons par la suite en deux sous ensembles : d’entrainement et de test.Utilisation de K-NN sur MNIST
Dans cette section, nous allons charger le jeu de données ainsi que le classifieur K-NN de Sickit Learn. Finalement on utilisera ce dernier pour effectuer une prédiction.
- Chargement des bibliothèques :
Scikit-Learn vient avec un ensemble de jeux de données prêt à l’emploi pour des fins d’expérimentations. Ces dataset sont regroupés dans le package sklearn.datasets.
On charge le package datasets pour retrouver le jeu de données MNIST. Par la suite, on charge la librairie Pandas : un utilitaire facilitant la manipulation des données en format tabulaire.
from sklearn.datasets import * import pandas as pd %matplotlib inline
- Chargement du jeu de données et une première vue sur ces dernières :
digit = load_digits() dig = pd.DataFrame(digit['data'][0:1700]) dig.head()
La fonction load_digits charge le jeu de données MNIST. Par la suite, on crée un DataFrame de la librairie Pandas qu’on nomme « dig » alimenté par le jeu de données qu’on vient de charger.
Finalement, on utilise l’instruction dig.head() pour afficher les cinq premières lignes de notre DataFrame (histoire de voir ce qu’on manipule comme données 🙂 ).
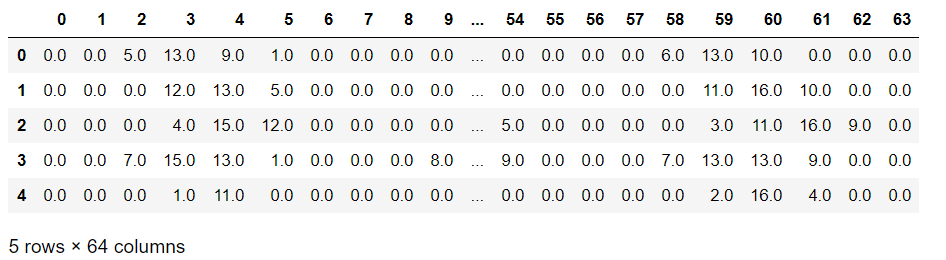
Note : On remarque que notre DataFrame contient 64 colonnes (de 0 à 63). Ce qui représente l’ensemble des valeurs de la matrice de taille  encodant un chiffre du jeu MNIST sous sa forme image.
encodant un chiffre du jeu MNIST sous sa forme image.
- Vérification de jeu de données :
digit.keys()
![]()
Dans notre cas, nous sommes intéressés par les colonnes : data et target. La variable « data » est la représentation en GrayScale d’un chiffre, et le target, représente son étiquette.
- Fonction d’affichage :
Comme on l’a déjà mentionné, le jeu de données MNIST représente des images de chiffres manuscrits. On peut s’amuser avec la librairie matplotlib pour créer une fonction de visualisation d’une image. 🙂
import matplotlib.pyplot as plt
def displayImage(i):
plt.imshow(digit['images'][i], cmap='Greys_r')
plt.show()
Note : Cette fonction est tout à fait optionnelle et nous pouvons s’en passer. Je l’ai intégré dans l’article juste pour des fins pédagogiques.
- Affichage des données
En guise d’exemple, visualisant la premier chiffre de notre jeu de données MNIST. Il s’agit d’un zéro. Pour se faire, on utilise la fonction displayImage qu’on vient de déclarer un peu plus haut :
#Affichage du premier élément du jeu de données displayImage(0)

Découpage du jeu de données
Lors de l’entrainement d’un algorithme de Machine Learning, la bonne pratique veut qu’on découpe notre jeu de données en jeu d’entrainement (Training Set) et jeu de test (Testing Set). Ainsi, nous pourrons tester les performances du modèle obtenu suite à l’entrainement de l’algorithme. Le test de performance se fait sur le testing Set qu’il n’a pas encore « vu ».
Pour notre cas, on divisera notre jeu de données comme suit :
- 75% de Training Set
- 25% de Testing Set
Pour y parvenir, on utilise la fonction train_test_split ().
from sklearn.model_selection import train_test_split train_x = digit.data # les input variables train_y = digit.target # les étiquettes (output variable) #découpage du jeu de données x_train,x_test,y_train,y_test=train_test_split(train_x,train_y,test_size=0.25) #0.25 pour indiquer 25%
Application de l’algorithme K-Nearst Neighbors
Tous les ingrédients sont là. Il nous reste plus qu’à entraîner un K-NN. Pour ce faire, la librairie Sickit Learn propose la classe KNeighborsClassifier qui implémente un algorithme K-NN.
Pour notre exemple, on va définir un classifieur à 7 voisins. Ainsi on obtient un 7-NN (car K = 7).
from sklearn.neighbors import KNeighborsClassifier KNN = KNeighborsClassifier(7) # on veut entrainer un 7-NN Classifier (on utilise 7 voisins) KNN.fit(x_train, y_train)
La fonction fit permet d’entraîner K-NN, le premier argument étant les input features qui correspond à l’encodage des chiffres en format matriciel. Le deuxième arguement indique pour chaque observation son étiquette (s’il s’agit du chiffre 5 ou 8 etc..).
Pour mesurer la performance de notre classifieur à  voisins, il faut le confronter à un jeu de données qu’il n’a pas encore « vu ». C’est pour cela qu’on utilise les 25% des observations du jeu MNIST qu’on a gardé lors du découpage de ce dataset.
voisins, il faut le confronter à un jeu de données qu’il n’a pas encore « vu ». C’est pour cela qu’on utilise les 25% des observations du jeu MNIST qu’on a gardé lors du découpage de ce dataset.
print(KNN.score(x_test,y_test))
Le score obtenu sur l’exactitude des prédictions sur le testing set est 0.986666 soit environ 98% de précision. Plutôt précis non ? 🙂
Prédictions et résultats
En prenant au hasard une observation du jeu de données MNIST. on regarde sa représentation graphique pour mettre en évidence la valeur du chiffre concerné.
import numpy as np test = np.array(digit['data'][1726]) test1 = test.reshape(1,-1) displayImage(1726)
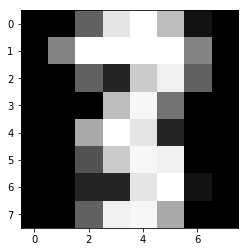
Je ne sais pas pour vous, mais ça m’a tout l’air d’un chiffre 3 😀
Regardant maintenant ce que prédira notre classifieur 7-NN pour cette même observation.
KNN.predict(test1)
Ce qui nous renvoie :
![]()
Et voila ! c’est bien un 3 🙂
Le code source de ce tutorial est sous format Jupyter Nootbook (extension du fichier ipynb), téléchargeable depuis le lien ci-dessous.
>> Téléchargez le code source depuis mon espace Github <<
Résumé
Dans cet article , nous avons appliqué l’algorithme K Nearest Neighbors sur le jeu de données MNIST en utilisant Scikit-learn. Ainsi nous avons pu reconnaître des chiffres manuscrits.
La précision obtenue est 98%, ce qui est très satisfaisant. Cependant, il est important de noter que le jeu de données MNIST est fortement pré-traité, ce qui rend l’apprentissage plus simple. Dans le monde réel, la reconnaissance de formes et d’objets dans une image est un sujet délicat. Principalement à cause de la taille des images leurs complexités et leurs contenus.
Je vous invite à essayer une nombre de voisins différents pour K-NN pour obtenir différents classifieurs. Comme ça vous pourrez comparer leurs performance par rapport à 7-NN.
J’espère que l’article vous aura plu. Si vous avez des questions, ou vous souhaitez partager la performance de votre K-NN, n’hésitez pas à poster un commentaire. 😉 Et si l’article vous plait, n’oubliez pas de le partager ! 😉
Bonjour,
Je vous remercie pour l’explication si claire et si simple.
pourquoi vous avez choisi k=7 ?
On a 10 chiffres différents, et comment l’algo de KNN se groupe les chiffres dans 7 groupes?
Merci en avance
Bonjour Nassim,
Lors de l’élaboration d’un modèle prédictif, on a pas de « apriori » sur ce dernier. Notamment pour le K-NN, on a pas de connaissance au préalable sur le nombre de voisins « K » optimal.
Dans ce sens, il faut tester plusieurs valeurs et garder la valeur qui vous convient à votre situation. Lors de ce stade de modélisation il faut utiliser un jeu de données de validation croisée pour retenir la bonne valeur de « K ».
Pour des raisons de simplification de la lecture de cet article, j’ai mis directement K=7.
Bonne journée 🙂
Merci beaucoup
Merci , explication claire et precis
Merci Seydi 🙂
Merci pour l’explication claire et précise. Ca donne de la confiance à une débutante comme moi.