
Dans l’un de mes articles précédents, j’ai parlé de la régression logistique. Il s’agit d’un algorithme de classification assez connu en apprentissage supervisé.
Dans cet article, nous allons mettre en pratique cet algorithme. Ceci en utilisant Python et Sickit-Learn.
C’est parti !

Pré-requis
Pour pouvoir suivre ce tutoriel, vous devez disposer sur votre ordinateur, des éléments suivants :
- le SDK Python 3
- Un environnement de développement Python. Jupyter notebook (application web utilisée pour programmer en python) fera bien l’affaire
- Disposer de la bibliothèque Sickit-Learn, matplotlib et numpy.
Vous pouvez installer tout ces pré-requis en installant Anaconda, une distribution Python bien connue. Je vous invite à lire mon article sur Anaconda pour installer cette distribution.
Jeu de données utilisé
Pour ce tutoriel, on utilisera le célèbre jeu de données IRIS. Ce dernier est une base de données regroupant les caractéristiques de trois espèces de fleurs d’Iris, à savoir Setosa, Versicolour et Virginica. Chaque ligne de ce jeu de données est une observation des caractéristiques d’une fleur d’Iris. Ce dataset décrit les espèces d’Iris par quatre propriétés : longueur et largeur de sépales ainsi que longueur et largeur de pétales. La base de données comporte 150 observations (50 observations par espèce). Pour plus d’informations, Wikipedia fournit des informations abondantes sur ce dataset.
Implémentation de la régression logistique sur Iris
Lors de cette section, je vais décrire les différents étapes que vous pouvez suivre pour réussir cette implémentation :
- Chargement des bibliothèques :
Premièrement, nous importons les bibliothèques numpy, pyplot et sklearn.
Scikit-Learn vient avec un ensemble de jeu de données prêt à l’emploi pour des fins d’expérimentation. Ces dataset sont regroupés dans le package sklearn.datasets.
On charge le package datasets pour retrouver le jeu de données IRIS.
#import des librairies l'environnement %matplotlib inline import numpy as np import matplotlib.pyplot as plt from sklearn import datasets
- Chargement du jeu de données IRIS
Pour charger le jeu de données Iris, on utilise la méthode load_iris() du package datasets.
#chargement de base de données iris iris = datasets.load_iris()
Comme on l’a évoqué précédemment, le dataset Iris se compose de quatre features (variables explicatives). Pour simplifier le tutoriel, on n’utilisera que les deux premières features à savoir : Sepal_length et Sepal_width.
Egalement, le jeu IRIS se compose de trois classes, les étiquettes  peuvent donc appartenir à l’ensemble {0, 1, 2}. Il s’agit donc d’une classification Multi-classes. La régression logistique étant un algorithme de classification binaire, je vais re-étiqueter les fleurs ayant le label 1 et 2 avec le label 1. Ainsi, on se retrouve avec un problème de classification binaire.
peuvent donc appartenir à l’ensemble {0, 1, 2}. Il s’agit donc d’une classification Multi-classes. La régression logistique étant un algorithme de classification binaire, je vais re-étiqueter les fleurs ayant le label 1 et 2 avec le label 1. Ainsi, on se retrouve avec un problème de classification binaire.
# choix de deux variables X = iris.data[:, :2] # Utiliser les deux premiers colonnes afin d'avoir un problème de classification binaire. y = (iris.target != 0) * 1 # re-étiquetage des fleurs
- Visualisation du jeu de données
Afin de mieux comprendre notre jeu de données, il est judicieux de le visualiser.
#visualisation des données plt.figure(figsize=(10, 6)) plt.scatter(X[y == 0][:, 0], X[y == 0][:, 1], color='g', label='0') plt.scatter(X[y == 1][:, 0], X[y == 1][:, 1], color='y', label='1') plt.legend();
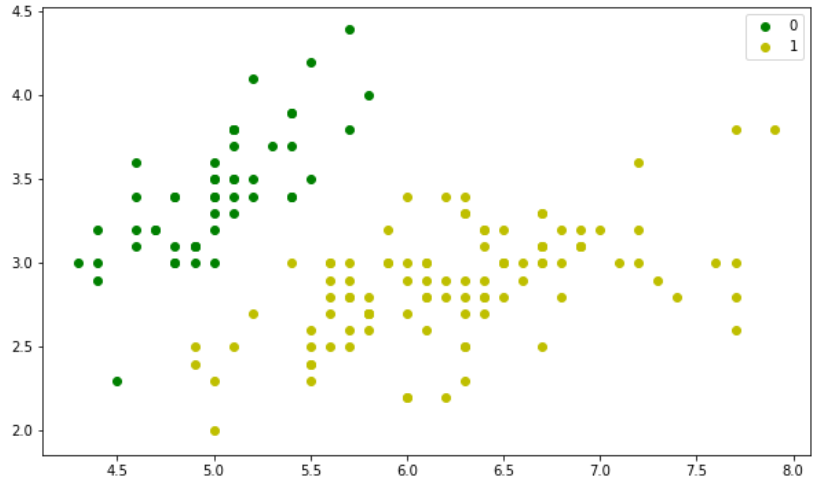
On remarque que les données de la classe 0 et la classe 1 peuvent être linéairement séparées. Une régression logistique serait capable de départager les deux classes.
Entrainement d’un modèle de régression logistique
Scikit Learn offre une classe d’implémentation de la régression Logistique. On instanciera cette classe pour entraîner un modèle prédictif.
from sklearn.linear_model import LogisticRegression # import de la classe model = LogisticRegression(C=1e20) # construction d'un objet de Régression logistique model.fit(X, y) # Entrainement du modèle
L’instruction model.fit(X, Y) permet d’entraîner le modèle.
- La variable
 comporte l’ensemble des observations qui serviront à l’entrainement de notre algorithme de Machine Learning
comporte l’ensemble des observations qui serviront à l’entrainement de notre algorithme de Machine Learning - la variable comporte l’étiquette de chacune de ces observations.
Prédire de la classe de nouvelles fleurs d’IRIS
Maintenant qu’on a entraîné notre algorithme de régression logistique, on va l’utiliser pour prédire la classe de fleurs d’IRIS qui ne figuraient pas dans le jeu d’entrainement. Pour rappel, on a utilisé que les variables explicatives « Sepal Length » et « Sepal Width » pour entrainer notre jeu de données. Ainsi, nous allons fournir des valeurs pour ces deux variables et on demandera au modèle prédictif de nous indiquer la classe de la fleur.
Iries_To_Predict = [
[5.5, 2.5],
[7, 3],
[3,2],
[5,3]
]
Dans la snippet de code ci-dessus, on a fourni quatre observations à prédire.
model.predict(Iries_To_Predict)
Le modèle nous renvoie les résultats suivants :
- La première observation de classe 1
- La deuxième observation de classe 1
- La troisième observation de classe 0
- La quatrième observation de classe 0
Ceci peut se confirmer visuellement dans le diagramme nuage de points en haut de l’article. En effet, il suffit de prendre les valeurs de chaque observation (première valeur comme abscisse et la deuxième comme ordonnée) pour voir si le point obtenu « tombe » du côté nuage de points vert ou jaune.
>> Téléchargez le code source depuis mon espace Github <<
Résumé
Lors de cette article, nous venons d’implémenter la régression logistique (Logistic Regression) sur un vrai jeu de données. Il s’agit du jeu de données IRIS. Nous avons également utilisé ce modèle pour prédire la classe de quatres fleurs qui ne figuraient pas dans les données d’entrainement.
Je vous invite à télécharger le code source sous son format Notebook et de l’essayer chez vous. Ainsi vous vous familiariserez mieux avec cet algorithme.
Finalement, j’espère que cet article vous a plu. Si vous avez des questions ou des remarques, vos commentaires sont les bienvenus. Pensez à partager l’article pour en faire profiter un maximum d’intéressés. 😉
Bonjour et merci pour le tuto.
Il y a juste une petite errur de casse Y au lieu de y dans le code d’entraînement du modèle : model.fit(X, Y).
Bonjour,
Merci pour la précision, effectivement une petite coquille s’est glissée. Je mets à jour l’article 🙂
Bonjour et merci pour le tutoriel. j’arrive pas à comprendre comment on peut dire que telle valeur appartient à l’espece Setosa, Versicolour et Virginica.
j’ai beau essayer de comprendre votre conclusion mais en vain.
Bonjour Aidara,
Vous pouvez reconnaitre l’espèce en question grâce au label dans votre jeu de données, par exemple les Setosa ont dans notre jeu de données le label 0 par exemple. Ainsi quand le classifieur prédira 0 cela veut dire qu’il pense qu’il s’agit de l’espèce Setosa.
Bon courage
merci