
Dans l’un de mes précédents articles, j’ai démystifié les concepts et définitions clés du Machine Learning. J’y ai évoqué les concepts d’apprentissage supervisé (Supervised Learning), et l’apprentissage non supervisé (Unsupervised Learning).
Dans cet article, nous verrons plus en détails l’apprentissage supervisé.
Qu’est ce que l’apprentissage supervisé (Supervised Learning) ?
L’apprentissage supervisé est le concept derrière plusieurs applications sympas de nos jours : reconnaissance faciale de nos photos par les smartphones, filtres anti-spam des emails, etc.
Plus formellement, étant donné un ensemble de données D, décrit par un ensemble de caractéristiques X, un algorithme d’apprentissage supervisé va trouver une fonction de mapping entre les variables prédictives en entrée X et la variable à prédire Y. la fonction de mapping décrivant la relation entre X et Y s’appelle un modèle de prédiction.

Les caractéristiques (features en anglais) X peuvent être des valeurs numériques, alphanumériques, des images… Quant à la variable prédite Y, elle peut être de deux catégories :
- Variable discrète : La variable à prédire peut prendre une valeur d’un ensemble fini de valeurs (qu’on appelle des classes). Par exemple, pour prédire si un mail est SPAM ou non, la variable Y peut prendre deux valeurs possible :

- Variable continue : La variable Y peut prendre n’importe quelle valeur. Pour illustrer cette notion, on peut penser à un algorithme qui prend en entrée des caractéristiques d’un véhicule, et tentera de prédire le prix du véhicule (la variable Y).
La catégorie de la variable prédite Y fait décliner l’apprentissage supervisé en deux sous catégories :
- La classification
- La régression
Les algorithmes de classification
Quand la variable à prédire prend une valeur discrète, on parle d’un problème de classification. Parmi les algorithmes de classification, on retrouve : Support Vector Machine (SVM), Réseaux de neurones, Naïve Bayes, Logistic Regression…
Chacun de ses algorithmes a ses propres propriétés mathématiques et statistiques. En fonction des données d’entrainement (Training set), et nos features, on optera pour l’un ou l’autre de ces algorithmes. Toutefois, la finalité est la même : pouvoir prédire à quelle classe appartient une donnée (ex : un nouveau email est il spam ou non).
Quand l’ensemble des valeurs possibles d’une classification dépasse deux éléments, on parle de classification multi-classes (Multi-class Classification). L’image suivante illustre les deux types de classifications.
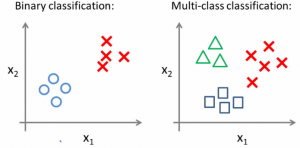
Dans l’image ci-dessus, les ronds en bleu représentent une classe (mail non spam par exemple), et les croix rouges peuvent représenter des SPAM. L’image à droite est une multi-class classification, car nous avons trois classes possibles (les triangles, les croix, et les carrés).
Les algorithmes de régression
Un algorithme de régression permet de trouver un modèle (une fonction mathématique) en fonction des données d’entrainement. Le modèle calculé permettra de donner une estimation sur une nouvelle donnée non encore vue par l’algorithme (qui ne faisait pas partie des données d’entrainement).
Les algorithmes de régression peuvent prendre plusieurs formes en fonction du modèle qu’on souhaite construire. La régression linéaire est le modèle le plus simple : Il consiste à trouver la meilleure droite qui s’approche le plus des données d’apprentissage. La fonction de prédiction sera donc une droite.
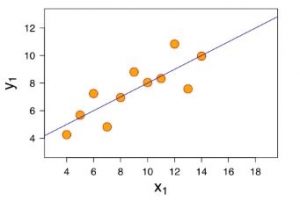
Le modèle prédit par l’algorithme de régression linaire sera de la forme  (
( et
et  sont les coefficients de la droite).
sont les coefficients de la droite).
Dans la vraie vie, supposer une corrélation linéaire entre les données n’est pas suffisant pour faire des modèles prédictifs complexes. Les données n’ont pas forcément une relation linéaire entre elles, et plusieurs variables prédictives peuvent être nécessaires pour effectuer prédiction réaliste. La régression polynomiale et la régression multivariée (à plusieurs variables) permettent de calculer des fonctions de mapping complexes qui s’adaptent bien aux données d’apprentissage.
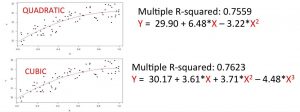
Dans cet exemple, nous avons deux fonctions polynomiales avec des degrés de polynôme différents. Toutes les deux peuvent être de bonnes prédictions pour les données affichées dans le graphe.
Généralement, plus on monte dans le degré du polynôme, plus nous avons des fonctions qui s’adaptent bien aux données.
Cet article introduit les notions de régression et de classification. Dans les prochains articles, j’entrerai plus en détail dans les algorithmes d’apprentissage supervisé.
Si l’article vous plait, ou que vous avez des remarques, n’hésitez de faire des commentaires et de partager l’article ! 🙂
Ping : Débuter en Machine Learning avec la formation d'Andrew NG - Mr mint le blogueur sur le Java et le big data
Ping : L'apprentissage non supervisé - Machine Learning - Mr mint le blogueur sur le Java et le big data
Ping : Régression linéaire en Python par la pratique - Apprendre le Machine Learning de A à Z
Bien expliqué 😉
Ping : Introduction au Naïve Bayes classifier - Apprendre le Machine Learning de A à Z
Ping : Créer son premier filtre Anti-spam avec Naïve Bayes et Python | Mr. Mint : Apprendre le Machine Learning de A à Z
Ping : 9 Algorithmes de Machine Learning que chaque Data Scientist doit connaitre | Mr. Mint : Apprendre le Machine Learning de A à Z
Ping : Overfitting et Underfitting : Quand vos algorithmes de Machine Learning dérapent ! | Mr. Mint : Apprendre le Machine Learning de A à Z
Ping : Machine Learning : 10 applications et cas d'usage pratiques
Ping : Gradient Descent Algorithm : Explications et implémentation en Python
Ping : Gradient Descent : Théorie et pratique... La magie du Machine Learning démystifiée ! | Mr. Mint : Apprendre le Machine Learning de A à Z
Merci beaucoup pour vos articles. Ils sont super clairs. Proposez-vous des cours vidéos en ligne ?
Bonjour Sina,
Merci pour votre commentaire. Pour le moment je ne propose pas de cours en ligne mais j’y réfléchi … 🙂
Je vous tiendrai au courant sur ce point.
Bonne journée
Tout simplement le meilleur cours introductif au machine learning sur internet
Ce cours me permet enfin d’associer mes connaissances en analyse de données au machine learning.
C’est justement ça le problème des documentations de ML sur le WEB. On se concentre sur des formules mathématiques ésotériques au lieu d’expliquer le concept et son utilité ou alors son usage dans le monde réel.
Merci, vraiment merci à vous. Je compte suivre après ce cours la formation d’Andrew NG.
Je constate avec stupéfaction que le ML n’est qu’une application stricte de concepts mathématiques relativement simples.
Merci Albert Stève pour votre commentaire 🙂
Concernant la formation d’Andrew NG, elle est excellente, je la recommande comme point de départ. Par contre, je tiens à préciser qu’elle est plutôt axée sur la théorie et il y a pas mal de notions et notations mathématiques dans le cours d’Andrew.
A bientôt !
Merciiiiiiiiiiiiiiiiiiiii beaucoupppppppppppppp pour votre explication
c’est trop clair. j’ai commencé à fixer et organiser mes idées sur les machine learning
Vous avez pas un livre ou un lien ou il y’a tout les articles??
Excellent
top top vraiment
bonjour,
vos explications sont tellement claires et facile à assimiler que je n’arrive pas à m’arrêter de passer d’un article à un autre.
en cas de besoin, je n’hésiterai pas à vous contacter.
merci bcp!