
L’Overfitting (sur-apprentissage), et l’Underfitting (sous-apprentissage) sont les causes principales des mauvaises performances des modèles prédictifs générés par les algorithmes de Machine Learning.
Dans cet article on verra ce que veut dire ces deux termes et dans quels cas ils se manifestent.

A quel point est-elle bonne ma fonction de prédiction ?
En apprentissage supervisé (Supervised Learning), un algorithme de Machine Learning va trouver une fonction de prédiction/approximation  , qui se basera sur des variables prédictives
, qui se basera sur des variables prédictives  et va approcher une variable cible
et va approcher une variable cible  tel que :
tel que :  .
.
Un des aspects importants à considérer dans cette fonction est : Comment se généralisera t-elle sur des données qu’elle n’a pas encore « vu » lors de la phase d’apprentissage ?
Cette question est importante car le but du Machine Learning est de prédire des résultats sur des données non vues par la fonction prédictive. Le but du jeu est que la prédiction faite soit la proche possible de la réalité et ce après que le modèle s’est entraîné sur des données d’apprentissage (Training Set).
En effet, quand un algorithme du Supervised Learning va produire une fonction/modèle de prédiction , il se basera sur des données d’apprentissage. La fonction produite va capturer toutes propriétés et corrélations présentes dans le Training Set.
Ces propriétés et corrélations sont propres au Training Set. C’est pour cela que les données d’apprentissage doivent être assez représentatives du problème métier. Plus le Training Set est représentatif du problème métier, mieux seront les corrélations capturées par le modèle prédictif. Par conséquent, le modèle de prédiction calculé à l’issu de la phase d’apprentissage sera mieux généralisable et permettra des prédictions plus précises sur des données qui ne sont pas présentes dans le Training Set.
Qu’est ce que l’Overfitting
L’Overfitting (sur-apprentissage) désigne le fait que le modèle prédictif produit par l’algorithme de Machine Learning s’adapte bien au Training Set.
C’est top ! c’est ce qu’on veut non 🤔 ?
Pas tout à fait. En effet, quand je dis que la fonction prédictive s’adapte bien au Training Set, je sous-entends qu’elle s’adapte même trop bien aux données d’apprentissage. Par conséquent, le modèle prédictif capturera tous les « aspects » et détails qui caractérisent les données du Training Set. Dans ce sens, il capturera toutes les fluctuations et variations aléatoires des données du Training Set. En d’autres termes, le modèle prédictif capturera les corrélations généralisables ET le bruit produit par les données.
Overfitting : un modèle trop spécialisé sur les données du Training Set et qui se généralisera mal
Quand un tel événement se produit, le modèle prédictif pourra donner de très bonnes prédictions sur les données du Training Set (les données qu’il a déjà « vues » et auxquelles il s’y est adapté), mais il prédira mal sur des données qu’il n’a pas encore vues lors de sa phase d’apprentissage.
On dit que la fonction prédictive se généralise mal. Et que le modèle souffre d’Overfitting.
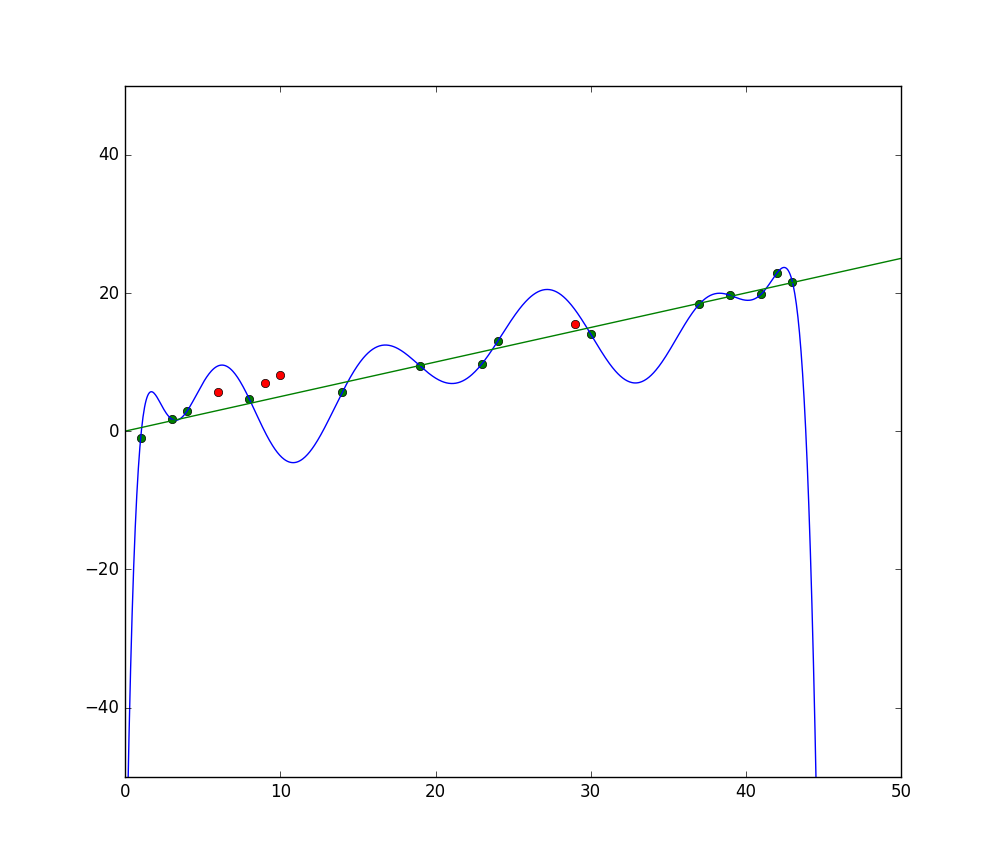
L’image ci-dessus montre un exemple d’Overfitting. Le tracé en bleu représente une fonction de prédiction qui passe par toutes les données du Training Set (points en vert). On voit bien que la fonction est instable (grande variance) et qu’elle s’écarte beaucoup des points rouges qui représentent des données non vues lors de la phase d’apprentissage (Test Set).
Qu’est ce que l’Underfitting
L’Underfitting (sous-apprentissage), sous entend que le modèle prédictif généré lors de la phase d’apprentissage, s’adapte mal au Training Set.
Autrement dit, le modèle prédictif n’arrive même pas à capturer les corrélations du Training Set. Par conséquent, le coût d’erreur en phase d’apprentissage reste grand. Bien évidemment, le modèle prédictif ne se généralisera pas bien non plus sur les données qu’il n’a pas encore vu. Finalement, le modèle ne sera viable car les erreurs de prédictions seront grandes.
Dans ce cas de figure, on dit que le modèle souffre d’Underfitting. On dit également qu’il souffre d’un grand Bias (biais).
Underfitting : un modèle généraliste incapable de fournir des prédictions précises
Le terme Bias sous-entend que le modèle présuppose une hypothèse forte lors de sa modélisation. Par exemple, supposer que le prix d’un appartement est linéairement corrélé à sa superficie. Dans ce cas de figure, la fonction de prédiction prendra en compte que la superficie de la maison comme variable d’entrée et la fonction de prédiction sera sous forme d’une droite rigide. Un tel modèle est assez pauvre (car il ne prend en compte que la superficie) et ne sera pas suffisant pour prédire précisément le prix d’un appartement dans la vie réelle.
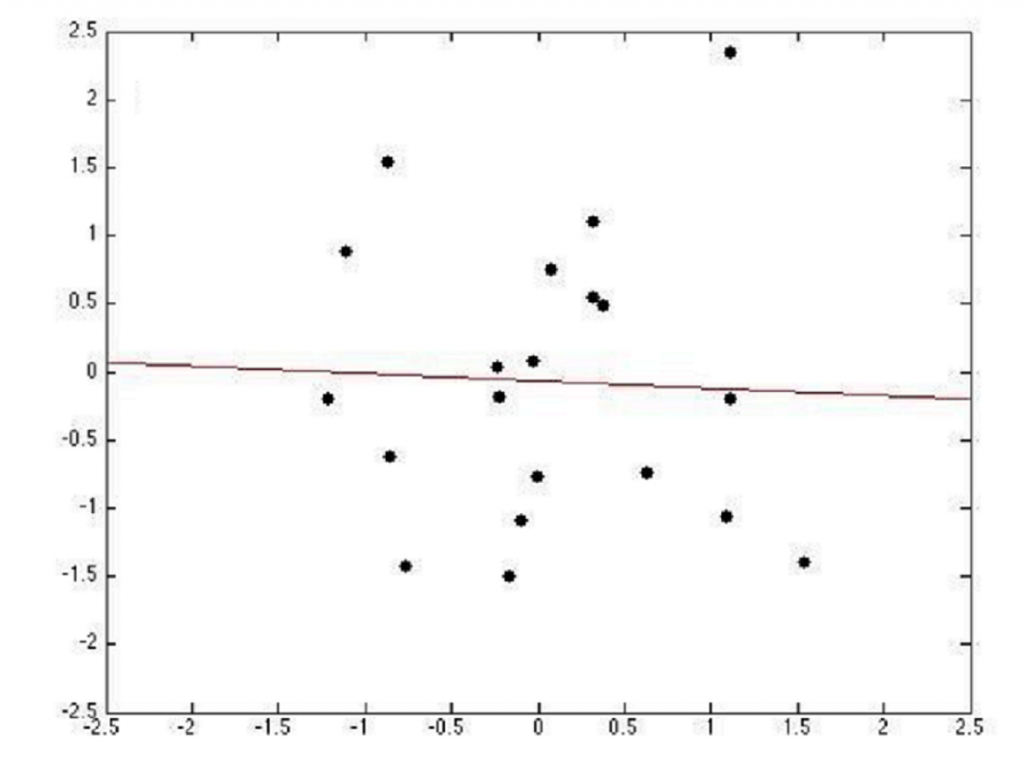
L’image ci-dessus montre un exemple d’Underfitting. La courbe approche les 4 points et l’erreur est grande pour les autres.
Le meilleur modèle est celui du juste milieu
Vous l’aurez bien compris, on cherche un modèle qui est au « juste milieu ». Il ne doit souffrir ni d’Underfitting ni d’Overfitting. En d’autres termes, il ne souffre ni d’un grand Bias ni d’une grande variance.
Trouver ce juste milieu est le challenge de chaque data scientist lors d’un projet de Machine Learning.
Dans mon article sur l’algorithme de Gradient Descent, j’ai parlé d’une fonction de coût d’erreur. Pour rappel l’algorithme de Gradient Descent permet de trouver le meilleur modèle prédictif en minimisant le coût d’erreur global de la phase d’apprentissage.
Quand l’algorithme de Machine Learning apprend depuis le Training Set, les paramètres du modèle prédictif vont s’affiner au fil du temps. En conséquence, le coût d’erreur sur le Training Set continuera à se réduire. Parallèlement, le coût d’erreur des prédictions sur les données de test (non vu par l’algorithme) se réduira également.
Mais si on continue à entrainer longuement le modèle, le coût d’erreur sur le Training Set continuera à se réduire. MAIS celui du Test Set pourra commencer à augmenter. Cette augmentation signifie que le modèle prédictif s’est trop spécialisé sur les données d’apprentissage. Le point où commence l’augmentation du coût d’erreur dans le Test Set est le commencement du Overfitting.
Le juste milieu est le point juste avant le commencement de l’augmentation du coût d’erreur dans le Test Set. C’est à ce stade que le modèle sera abouti et bien généralisable.
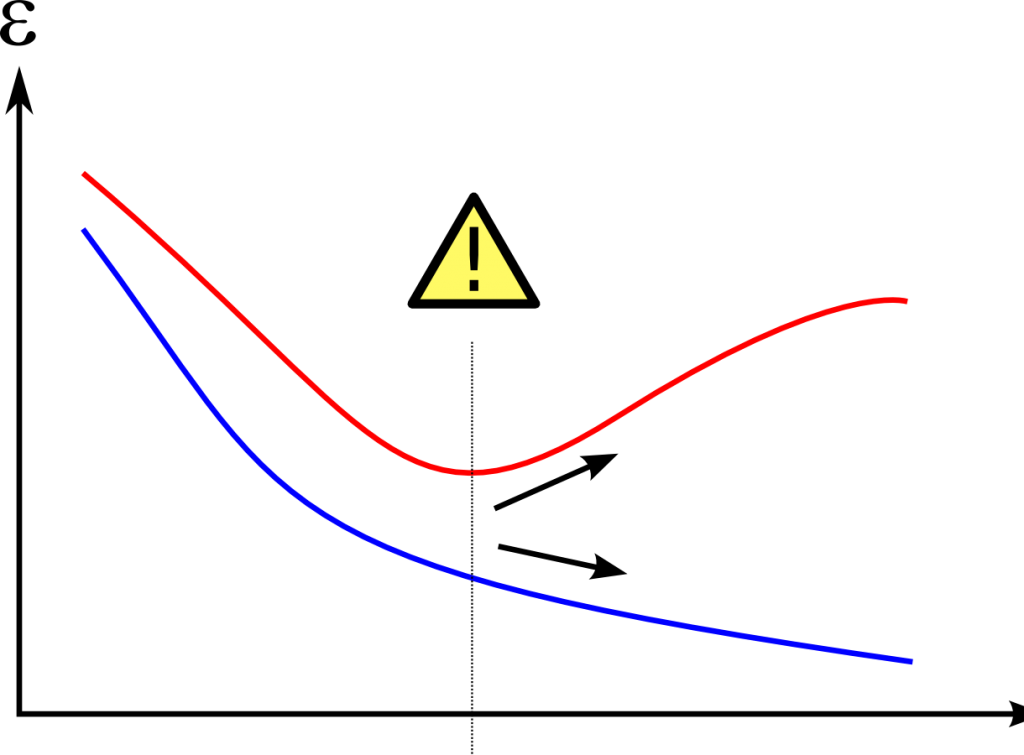
Le tracet en bleu signale le coût d’erreur global du modèle à travers le temps sur le Training Set. Celui en rouge représente la même information mais sur un Test Set. Le picto de warning représente le point optimal pour le modèle prédictif. A droite de ce point on tombe dans le Overfitting, et à gauche on tombe dans l’Underfitting.
Résumé
Dans cet article nous avons vu les notions d’Overfitting et Underfitting. On a vu également comment retrouver le « juste milieu »qui permet de retrouver le meilleur modèle pour vos prédictions.
En réalité, il existe des méthodes plus élaborées pour retrouver ce « juste milieu » et éviter l’Overfitting. Parmi ces méthodes, il y a la validation croisée que j’aborderai lors des prochains articles.
Si vous avez des questions, n’hésitez pas à me les poser dans un commentaire et si l’article vous plait, n’oubliez pas à le faire partager ! 😉
Bonjour ,j’ai trouvé votre article très intéressant . A propos de l’overfitting , j’essaie de faire des prédictions sur des données en utilisant notamment les algorithmes KNN,Naives Bayes,Random Forest ,Multilayer Perceptron et SVM en utilisant l’outil WEKA et je suspecte un overfitting, comment y remédier? merci
Bonjour,
Les librairies comme Weka ou Scikit learn pour Python ( tout autre librairie) ne sont que des implémentation d’ algorithmes ML. Bien sur, il faut connaitre les limites théoriques de l’algorithme que vous souhaitez utiliser pour trouver la meilleure parade pour éviter l’overfitting.
Si je prends l’exemple KNN, augmenter la valeur de K (le nombre de voisins) permet (généralement) d’améliorer la prédiction car on se base sur la similarité de plusieurs voisins pour prendre une décision. Passer un certain seuil K on tombe dans l’overfitting.
Pour remédier à l’overfitting, il faut appliquer les techniques de découpage du jeu de données (jeu entrainemen, jeu de validation croisée et jeu de test), ainsi que les techniques de régularisation (Lasso, ElasticNet etc…). Finalement, le jeu de données utilisé à l’entrainement de l’algorithme doit être significatif et représentatif du phénomène que vous souhaitez modéliser.
Quelles sont les différentes techniques de régularisations en apprentissage automatique ?
Bonjour Ahmed,
Il existe plusieurs techniques de régularisations. A savoir, Lasso, Ridge et ElasticNet. Chacun à des propriétés qui lui sont propres. Elle feront l’objet d’articles futur.
Bonne journée
bonjour je fait un prédiction d’un data courant l’état si c’est en défaut ou sain. en premier j’utilise le classification SVM sur App Matlab sans problème, mais là j’utilise la régression polynomiale et j’utilise Matlab pour faire mon algo
et mon problème je sait pas comment faire pour avoir le picto de warning qui représente le point optimal pour le modèle prédictif. pouvez vous me donner le formule pour avoir cet point optimal? Merci
Bonjour Nenely,
Je ne suis pas sur d’avoir saisi votre question, votre problème est-il un problème de classification ou de régression ?
Le picto de warning est juste à des fins d’illustration. Il n’y a pas lieu de l’avoir pour s’assurer que votre modèle est bon ou non.
Bien à vous
Bonjour,
Comment faire pour avoir avoir le meilleur modèle ou celui du juste milieu?
merci
Bonjour,
Pour trouver un bon modèle, il faut surtout qu’il ne tombe ni dans l’underfitting ni l’overfitting. Cela peut se tester en utiliser une mesure de performance et les méthodes de validations de croisées pour selectionner un modèle parmi plusieurs (celui ayant le meilleur score via la mesure de performance retenue).
Merci beaucoup!!!!!!!
Bonjour Younes,
Merci beaucoup pour votre article, vous expliquez bien les concepts.
A titre personnel, je développe des algorithmes de trading automatique et je suis en plein dans la problématique de la sur-optimisation et de la sous-optimisation. Avec l’expérience, j’ai développé mes propres contrôles qui me permettent de savoir si une stratégie est robuste ou non. C’est à dire qu’elle n’est ni sur-optimisée ni sous-optimisée.
Si cela vous intéresse, j’ai publié une partie de mes tests sur mon blog :
https://artificall.com/prorealtime/backtest/evaluate-the-robustness-of-trading-strategy-at-first-glance/
J’utilise le walk-forward optimization pour définir les paramètres des variables impliquées dans la prise de décision. Cela me permets de savoir quand ouvrir et quand clôturer une position. Connaissez-vous le walk-forward optimization ? Je serais ravis si vous pouviez présenter cet méthode sur votre blog, afin d’avoir votre point de vu.
Belle journée,
Vivien
Bonjour,
Réponse en MP 🙂
Younes