
Dans l’article précédent, nous avons parlé de l’apprentissage supervisé (Supervised Learning). Dans cet article, nous parlerons de l’apprentissage non supervisé (Unsupervised Learning) qui est la deuxième branche du Machine Learning.
Qu’est ce que l’apprentissage non supervisé (Unsupervised Learning) ?
A l’inverse de l’apprentissage supervisé (Supervised Learning) qui tente de trouver un modèle depuis des données labellisées  , l’apprentissage non supervisé prend uniquement des données sans label (pas de variable à prédire Y). Un algorithme d’Unsupervised Learning va trouver des patterns ou une structuration dans les données.
, l’apprentissage non supervisé prend uniquement des données sans label (pas de variable à prédire Y). Un algorithme d’Unsupervised Learning va trouver des patterns ou une structuration dans les données.
Les algorithmes de Clustering rentrent dans la catégorie de Unsupervised Learning. Ils permettent de regrouper en des ensembles, les données qui sont similaires.
Le Clustering, à quoi ça pourrait bien servir ?
Trouver des patterns dans les données grâce aux algorithmes de Clustering, c’est bien sympa, mais à quoi cela pourrait bien servir ?
A première vue, on pourrait penser que le Clustering a peu d’utilité dans les applications de la vraie vie. Mais détrompez-vous ! Les applications de cette technique sont nombreuses. Quand vous vous demandez comment Amazon fait pour recommander les bons produits, ou encore YouTube qui vous propose des vidéos en relation avec vos attentes, ou encore Netflix qui vous propose de bons films, tout ça c’est du Clustering !
L’efficacité d’implémentation d’un algorithme de Clustering peut permettre une augmentation significative du chiffre d’affaires d’un site e-commerce comme pour le cas Amazon (lien en anglais)
L’algorithme K-Means pour le Clustering
L’algorithme K-Means (K-moyennes) est le plus connu dans l’Unsupervised Learning. Il s’agit d’un algorithme de Clustering. Ce dernier va mettre dans des « zones » (Cluster), les données qui se ressemblent. Les données se trouvant dans le même cluster sont similaires.
L’approche de K-Means consiste à affecter aléatoirement des centres de clusters (appelés centroids), et ensuite assigner chaque point de nos données au centroid qui lui est le plus proche. Cela s’effectue jusqu’à assigner toutes les données à un cluster.
L’illustration par une image, du résultat d’exécution de l’algorithme K-Means vous permettra d’en appréhender le fonctionnement.
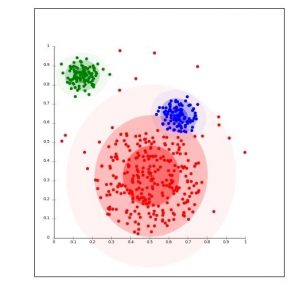
Dans cet image, on reconnait trois clusters : (un en rouge, un bleu et un vert).
Dans cet article, nous n’avons fait qu’effleurer l’algorithme K-Means et le Clustering en général. Je ferai un article plus détaillé sur ces notions dans un futur article.
Si vous avez des questions ou des remarques, n’hésitez pas à m’écrire via un commentaire. Et si l’article vous plait n’hésitez pas à le partager ! 😉
Ping : Apprendre le Machine Learning avec la formation d'Andrew NG - Apprendre le Machine Learning de A à Z
Ping : 9 Algorithmes de Machine Learning que chaque Data Scientist doit connaitre - Apprendre le Machine Learning de A à Z
Ping : Tout ce que vous voulez savoir sur l'algorithme K-Means
merci pour vos articles très édifiants.
1) Je souhaite savoir qu’est ce qui rentre dans l’apprentissage non supervisé en dehors du clustering?
2) quelles sont les nuances ,si elles existent entre les mots clustering , classification et classement
3)En effet, j’ai lu et utilisé un cours traitant de la classification supervisée et non supervisée pour mon mémoire .
Dans ce cours il ressort que:
3.1. Classification supervisée
Contexte : On considère une population divisée en q groupes d’individus différents. Ces groupes
sont distinguables suivant les valeurs de p caractères X1, . . . , Xp, sans que l’on ait connaissance
des valeurs de X1, . . . , Xp les caractérisant. On dispose
* de n individus avec, pour chacun d’entre eux, les valeurs de X1, . . . , Xp et son groupe d’appartenance,
*d’un individu ω* de la population avec ses valeurs de X1, . . . , Xp, sans connaissance de son groupe d’appartenance.
Objectif : Partant des données, l’objectif est de déterminer à quel groupe l’individu ω* a le plus
de chance d’appartenir.
3.2. Classification non-supervisée
Contexte : On considère n individus Γ = {µ1, . . . , µn} extraits au hasard d’une population. Pour
chacun d’entre eux, on dispose de p valeurs de p caractères X1, . . . , Xp .
Objectif : Partant des données, l’objectif est de regrouper/classer les individus qui se
ressemblent le plus/qui ont des caractéristiques semblables.
Méthodes : Pour atteindre l’objectif, plusieurs méthodes sont possibles pour la classification non supervisée. Parmi elles, il y a:
l’algorithme de Classification Ascendante Hiérarchique (CAH),
l’algorithme des centres mobiles (K-means),
l’algorithme de Classification Descendante Hiérarchique (CDH),
la méthode des nuées dynamiques (partitionnement autour d’un noyau),
la méthode de classification floue,
la méthode de classification par voisinage dense.
3-a) Que signifie votre expression « Un algorithme d’Unsupervised Learning va trouver des PATTERNS dans les données »?
3-b) A défaut de la réponse à la question 3-a) au moment où je vous écris , d’après ce qui précède (définition de la classification non supervisée), on est tenté de dire (puisque nous avons des données sans label) que la classification non supervisée n’est rien d’autre que du clustering et donc une sous catégorie de l’apprentissage non supervisé . Qu’en est-il exactement de ces deux concepts?
4) Pour ne pas repartir sur l’article sur l’apprentissage supervisé pour mon commentaire, permettez-moi de le faire ici. Ainsi, d’après ce qui précède (définition de la classification supervisée), on est tenté de dire (puisque l’algorithme apprend à affecter à la nouvelle donnée une classe ) que la classification supervisée n’est rien d’autre que la classification (au sens de votre article sur l’apprentissage supervisé ) donc une sous catégorie de l’apprentissage supervisé . Qu’en est-il exactement de ces deux concepts?
Merci de m’éclairer afin que je puisse confirmer ou infirmer mon résumé entre les concepts classification et apprentissage .
Wow ! Super commentaire, je tenterai d’y répondre au mieux 🙂
3-a) Que signifie votre expression “Un algorithme d’Unsupervised Learning va trouver des PATTERNS dans les données”? ==> Trouver un pattern dans le sens des similarités notamment via une mesure de similarité. Par conséquent, un algo d’apprentissage non supervisé regroupe par clusters les éléments se ressemblants.
3-b) les algos que vous avez cités sont des variantes qui servent à un même but, à savoir créer des clusters. Certains algo comme CAH et le CDH sont hiérarchique c’est à dire, ils créent des arborescences de clusters qu’on appelle les dendrogrammes. Le CAH et CDH différent dans la façon de construire ce dendrogramme. Quant à K-Means il s’attend à ce qu’on lui fournisse le nombre K de clusters et crée des clusters exclusives (une observation n’appartient qu’à a un et un seul cluster à la fois).
4) je ne suis pas sur d’avoir compris la question, mais dans certains litteratures francophone de statistique, on retrouve les terme « classification » pour designer le clustering. ce qui porte confusion. personnellement je préfére les termes en anglais qui enlèvent cette ambiguité. Par conséquent, sur le site, quand je parle de classification cela sous entend l’apprentissage supervisé de classification. Et quand je dis Clustering, j’entends le regroupement par clusters dans l’apprentissage non supervisé.
Bien à vous
J’adore ce cours !
Un travail fantastique et remarquable
Encore merci !
Merci Albert Stève pour votre commentaire 🙂
Bonjour,
merci pour tous vos articles.
J’ai une requête concernant K-means (qui pourrait donner lieu à nouvel article) : le choix de l’initialisation des centres étant primordial pour la détermination finale, pourriez vous expliquer comment on peut optimiser ce choix (j’ai entendu vaguement parler de K-means ++ mais je n’ai pas bien compris et peut-être existe-t-il d’autres alogorithmes concurrents) ?
Cordialement
Bonjour Laurent,
Effectivement l’initialisation initiale des centroides est primordiale pour obtenir de bons cluster. la méthode la plus naive consiste à prendre au hasard K points du data set et lancer le clustering.
K-Means++ est une méthode plus intelligente d’initialisation des centroides. L’idée est de prendre des points les plus éloignés les uns des autres comme centroids. Il est prouvé que cette méthode réduit le temps de convergence tout en évitant les minimums locaux.
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
D’ailleurs K-Means++ est la stratégie par défaut utilisé par Scikit Learn.
Ps : effectivement ça sera l’idée d’un nouvel article. 🙂
Au plaisir