
La visualisation des données (Data visualisation / Dataviz) est un domaine familier chez presque, tous les data scientist. Elle permet de tirer rapidement des informations grâce aux représentations graphiques.
La visualisation des données s’incorpore dans diverses phases du workflow d’un projet de Data Science. Notamment lors de l’exploration de données, visualisation des performances d’un Algorithme de Machine Learning ou encore pour offrir un support visuel intuitif pour présenter les conclusions que le Data scientist aura déduit à la suite de ses travaux de modélisations.

Pourquoi faire de la Dataviz
Une image vaut mille mots
Explorer les données
Visualiser les données peut sembler superflu. Toutefois le cerveau humain assimile plus facilement les informations au format visuel que dans une autre forme. Tirer le meilleur parti de cette faculté est primordial pour un projet de Data Science. En effet, les Data Scientists ont souvent affaire à des quantités de données multidimensionnelles astronomiques. Par conséquent, comprendre de telles quantités de données est possible grâce à la Data Visualization.
Communiquer ses idées
Notre faculté naturelle à comprendre les données visuelles permet souvent, de faire passer un message complexe d’une façon aisée. Le Data scientist est quelqu’un qui jongle entre les statistiques, la programmation et les données à haute dimension… mais communique aussi avec les décideurs de l’entreprise. Ces derniers n’ont pas forcément de grandes compétences techniques comme celles d’un Data Scientist.
Le Data scientist usera de la Dataviz pour communiquer avec le management
Pour communiquer avec eux de façon efficace, il n’y a pas mieux que de faire quelques visualisations et graphiques pour expliquer des tendances ou expliquer des résultats. Les décideurs et les gens du métier sont des personnes à l’aise avec des outils comme Microsoft Excel qui permet de produire aisément des Dashboards et des graphiques. Par conséquent, le Data scientist a intérêt de profiter de ce terrain de compréhension commun pour véhiculer ses conclusions et ses idées.
Statistiques Vs Dataviz
Les statistiques permettent de résumer les caractéristiques principales d’un jeu de données à l’aide de métriques numériques. Cependant, se baser uniquement sur ces chiffres pour tirer des conclusions sur un jeu de données (ou une feature du jeu de données) peut conduire à des déductions erronées.
La meilleure illustration du fait que les statistiques à elles seules ne suffisent pas, est le quartet d’anscombe. Il s’agit d’un ensemble de 4 jeux de données fictifs construit par le statisticien Francis Anscombe dans le but de montrer l’importance de la visualisation des données.
Ces jeux de données sont des couples de valeurs  . Chaque jeu de données contient 11 couples.
. Chaque jeu de données contient 11 couples.
Regardons à quoi ressemble ces jeux de données :
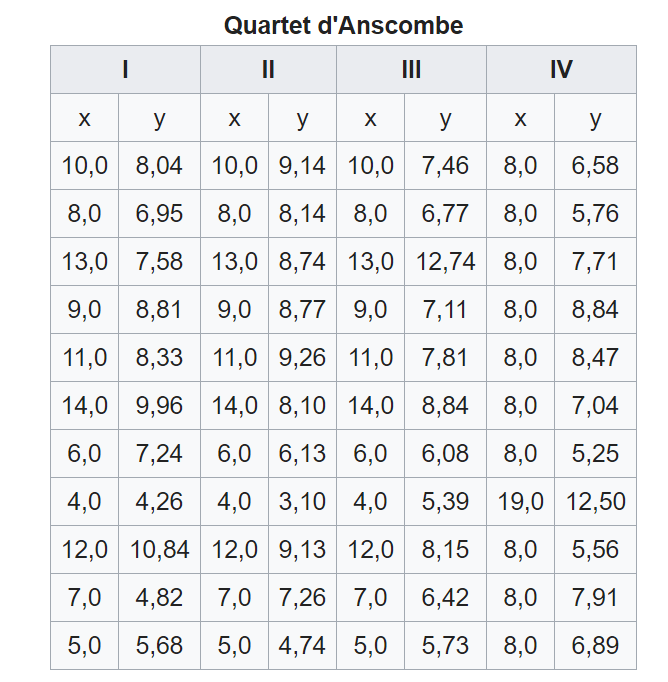
De prime abord, en regardant ces quatre jeux de données, rien ne nous saute aux yeux. Certes, quelques chiffres se répètent, mais rien ne semble indiquer une ressemble entre ces quatre jeux de données.
En utilisant les statistiques descriptives pour calculer certaines métriques basiques comme la moyenne et la variance. Ainsi qu’en appliquant une régression linéaire pour retrouver la meilleure droite qui fit ces jeux de données, on remarque que toutes les valeurs de ces métriques sont identiques pour les quatres Dataset.
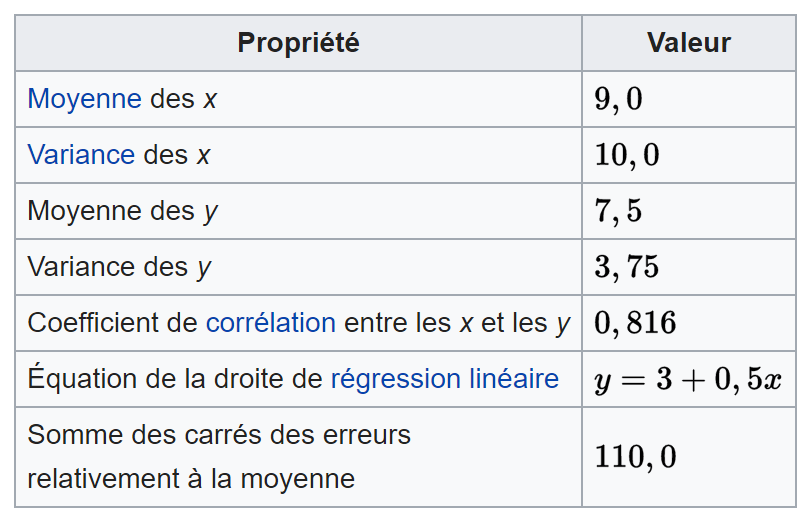
En se basant sur ces métriques statistiques uniquement, on pourrait se dire qu’il s’agit de jeux de données identiques (bien les valeurs des couples indiquent autrement). Troublant…. non ? 😕
Maintenant, regardant la visualisation de ces points dans un plan 2D et dessinons la droite de régression linéaire 
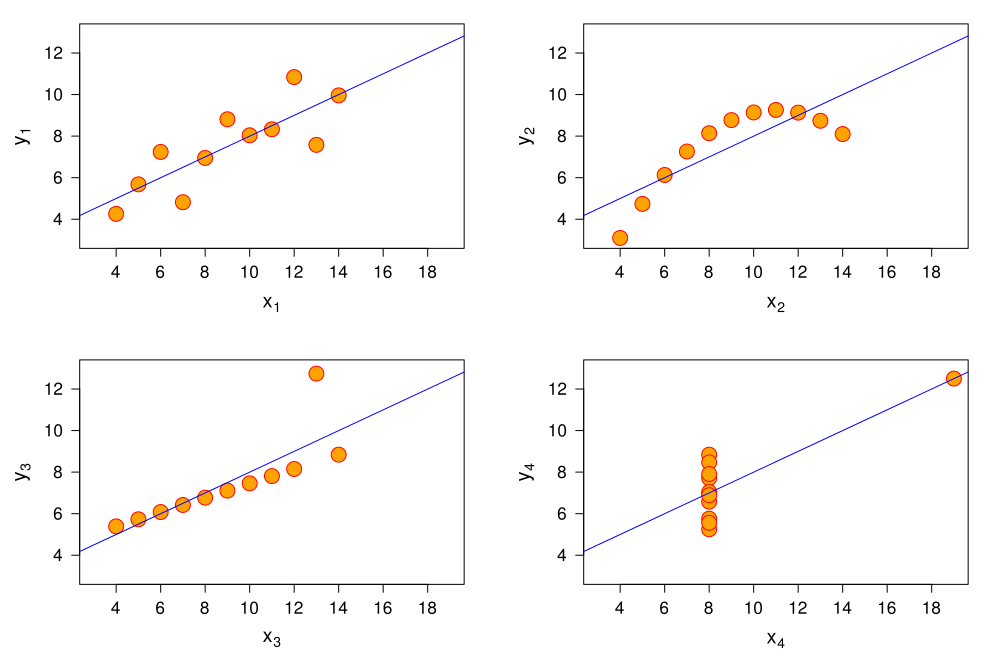
On remarque deux choses :
- Les quatre jeux de données sont fondamentalements différents !
- La droite de la régression linéaire qui représente le meilleur fit au jeu de données n’est toujours le choix le plus adapté.
Pour les jeux de données 2 et 4, on remarque qu’une régression linéaire n’est certainement pas le meilleur choix. Pour le 2éme jeu de données sous forme de parabole, une régression polynomiale sera certainement plus convenable. Pour le 3éme jeu de données, en enlevant le point outlier se trouvant seul en haut, on aurait pu obtenir une meilleure courbe de régression linéaire. Finalement, pour le 4éme jeu de données, la courbe de régression linéaire calculée est tout bonnement inefficace comme fonction de prédiction.
Pour accentuer l’importance de la visualisation des données en Data science, je partage avec vous une vidéo Youtube, faite par Autodesk. Elle montre des graphiques complétement différents sans que les métriques statistiques les concernant ne soient modifiées.
Conclusion
Nous venons de voir l’importance de la Dataviz en Data Science. Adoptez le bon réflexe en visualisant toujours vos données pour mieux les comprendre. Finalement, les statistiques et la Dataviz doivent être utilisées en tandem pour tirer les meilleures conclusions.
Une multitude d’outils existent qui simplifient la visualisation de vos données, notamment Tableau Software ou encore QLikeview. Toutefois, il est possible de faire des visualisations puissantes à l’aide de Python.
Finalement, il existe une multitude de types de visualisations et de graphes qu’un data scientist peut utiliser. Chacune est adaptée à une situation et type de données différent. Lors des prochains articles, nous verrons quels sont les visualisations et graphes qu’un Data Scientist sera le plus souvent amené à utiliser.
J’espère que l’article vous a plu. si vous avez des questions, n’hésitez pas à me les poser par un commentaire. 🙂
waohou!!
Adoptez le bon réflexe en visualisant toujours vos données pour mieux les comprendre.
Pour la dernière courbe (X4,Y4) , il me semble que même en enlevant l’outlier, on ne peut prédire Y en fonction de X par une droite car on a une droite verticale d’équation X=8
Ping : Anaconda, une distribution pour la Data Science et le Machine Learning - IntoData