
Bien que les statistiques soient importantes lors de la phase d’exploration de données, ces dernières ne sont pas suffisantes. L’article précédent montre à quel point la visualisation de données (Dataviz) est importante en Data Science.
Visualiser les données peut s’effectuer de plusieurs manières. Cela se décide, entre autres, en fonction du type de données qu’on souhaite analyser, le nombre de features impliquées..etc. Toutefois, certains graphes et visualisations reviennent souvent lors de la phase d’exploration de données qu’effectue tout Data Scientist lors d’un projet de Data Science.
Cet article regroupe les visualisations de données les plus courantes que vous serez amenés à utiliser lors de vos explorations de données. Pour chaque type de graphique, j’indiquerai dans quels cas il doit être utilisé et pour quel type de données il convient.
Univariate Data Visualisation
L’exploration univariée avec des plot univariés permet de comprendre la distribution d’une feature. Elle donne un aperçu visuel sur les caractéristiques de la feature analysée. Notamment, la concentration des données, les valeurs minimum et maximum… etc
Histogramme
un histogramme est un graphique permettant de représenter la répartition des valeurs d’une variable continue (Continuous Data). Chaque colonne de l’ histogramme représente un intervalle de valeurs. La hauteur des colonnes indique le nombre d’instances dans cet intervalle. L’examen de l’histogramme permet de se faire une idée claire sur la distribution des valeurs de la feature analysée.
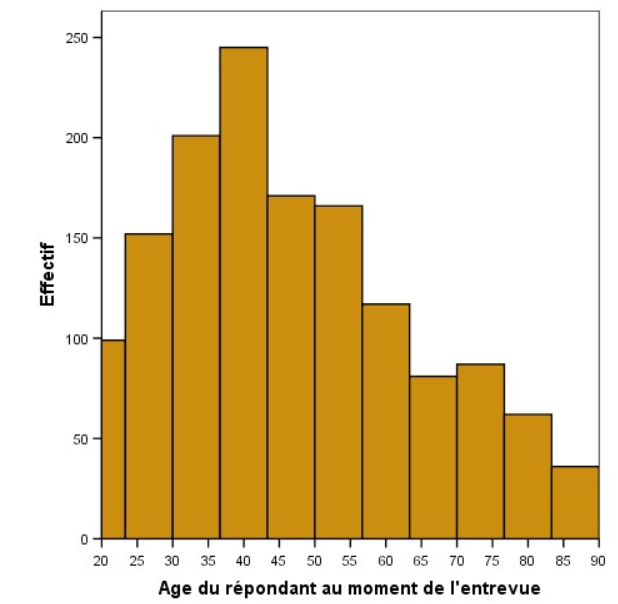
En analysant la feature « Age » de cet échantillon, on remarque que l’age typique est compris entre 40 et 50 ans, car c’est là que se situe la majorité des observations.
Bar Plot
Les Bar Plots sont utilisés pour visualiser des données qualitatives (Categorical Data). Chaque « Barre » d’un bar plot représente une catégorie (modalité) et la hauteur de la barre indique la taille du groupe faisant partie de cette catégorie.
Rappelez vous que les Bar Plot servent pour les Categorical Data alors que les Histogrammes servent pour les données continues (Continuous Data). Pour ne pas confondre ces deux graphiques, je vous conseille de lire cet article (en anglais).
Box Plot
Les boites à moustaches (Box Plot) permettent de visualiser plusieurs paramètres statistiques d’une feature. Notamment la médiane, l’écart interquartile (IQR) et la valeur maximale et minimale de la distribution. La représentation des informations des Box Plot est plus compacte que celle d’un histogramme, Toutefois, le degré de détails des informations délivrées par un Box Plot est moindre.
Nous pouvons avoir une idée de la tendance centrale des valeurs de chaque boite en observant la position de la médiane. Si la médiane n’est pas au centre, on peut juger de la symétrie de la distribution (aplatissement et asymétrie). Par ailleurs, en se basant sur la longueur de la boite, il est possible d’estimer la variabilité des valeurs pour chaque sous-groupe.
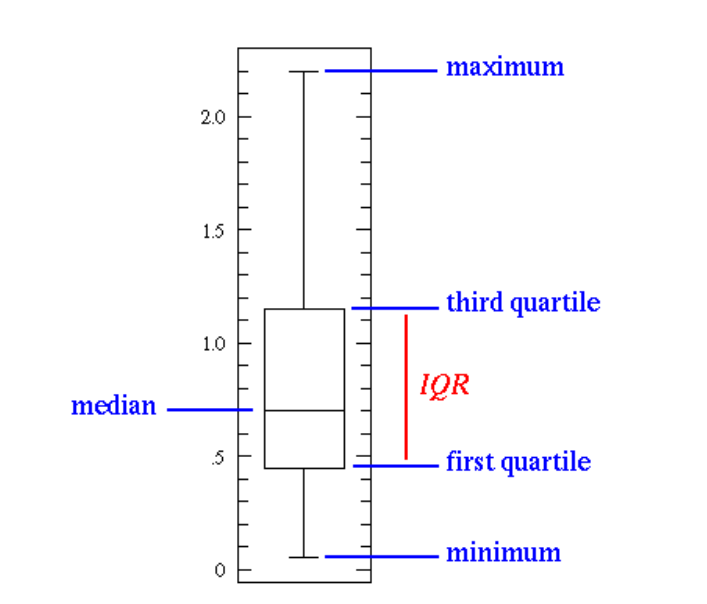
Utilisez les box plot pour visualiser des données discrètes ou continues. Notamment pour voir la répartition des données ainsi que l’existence des outliers.
Voici une représentation de la taille des fleurs d’Iris (du Iris Data Set) faite à l’aide de Python.
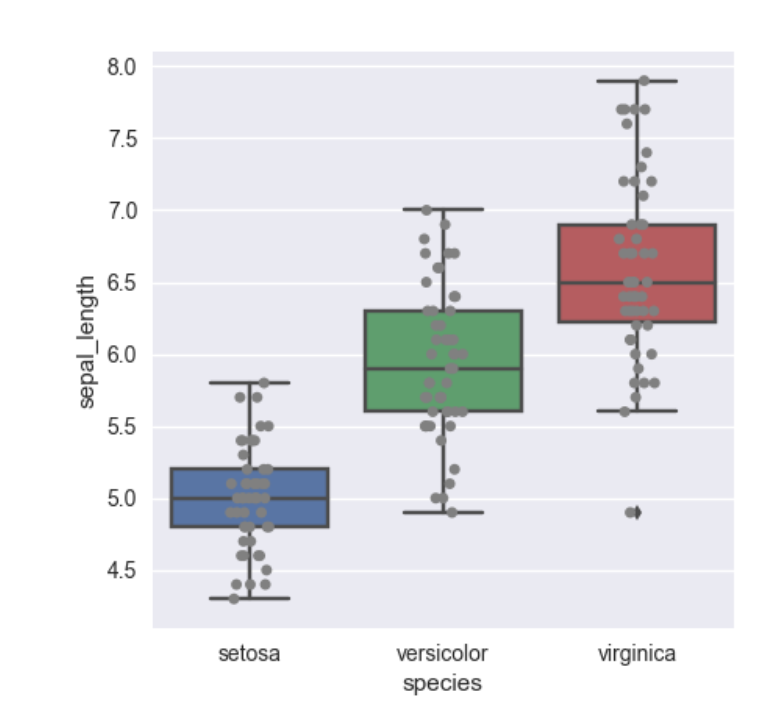
Source : python-graph-gallery.com
Multivariate Data Visualisation
La visualisation multivariée permet de représenter graphiquement deux features (2D) ou plus. Quand il s’agit de deux variables, on parle de Bivariate Visualisation et si c’est plus de deux features on parle de Multivariate Visualisation.
Scatterplot Matrices
Les Scatter Plot Matrices (Diagrammes de dispersion) permettent de visualiser la corrélation entre deux variables continues. On met la première feature sur l’axe des abscisses (X) et la deuxième sur les ordonnées (Y). La dispersion des points indique la relation entre les deux features.
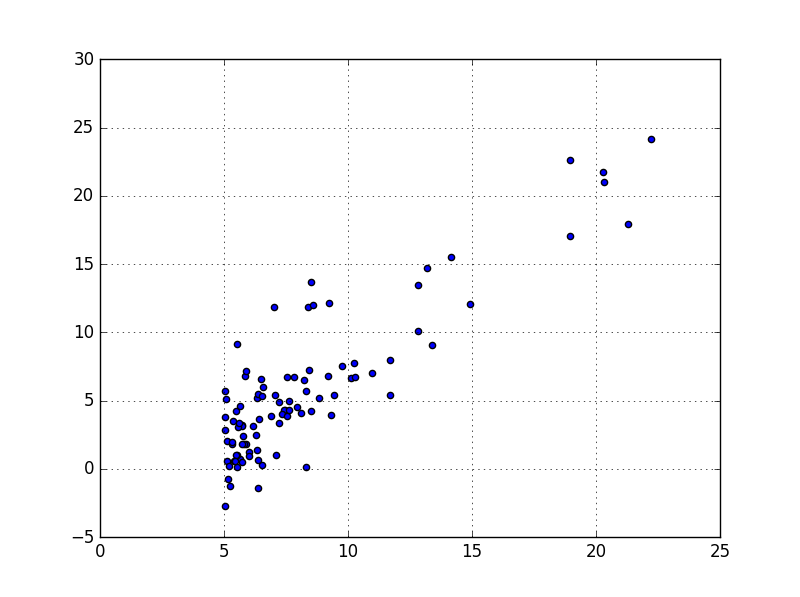
Bubble Chart
Les Graphes à Bulles (Bubble Chart) est un graphique à trois dimensions. Chaque triplet ( ,
, ,
, ) est tracé sous la forme d’un disque qui exprime deux des valeurs
) est tracé sous la forme d’un disque qui exprime deux des valeurs  à travers l’emplacement (
à travers l’emplacement ( ,
, ) du dique et la troisième à travers sa taille. En d’autres termes la taille du disque, représente la « grandeur » du phénomène observé.
) du dique et la troisième à travers sa taille. En d’autres termes la taille du disque, représente la « grandeur » du phénomène observé.
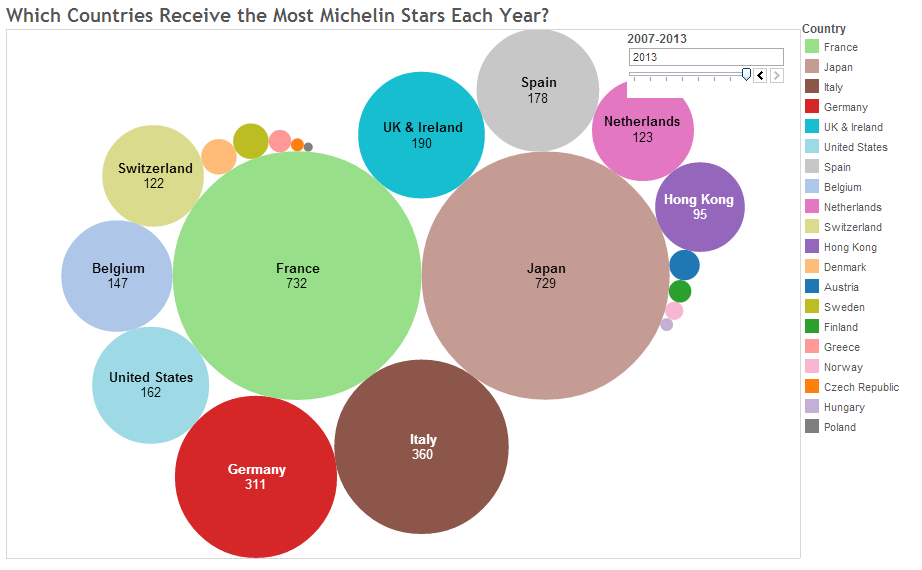
Dans cette illustration, la taille de chaque disque représente le nombre d’étoiles Michelin obtenues par chaque pays.
Parallel Coordinates
Les coordonnées parallèles (Parallel Coordinates) est un graphique permettant de représenter un jeu de données avec  dimensions (avec
dimensions (avec  ). L’axe X dans un graphique de Parallel Coordinates listera toutes les N features qu’on veut visualiser. L’axe des ordonnées Y représente les valeurs.
). L’axe X dans un graphique de Parallel Coordinates listera toutes les N features qu’on veut visualiser. L’axe des ordonnées Y représente les valeurs.
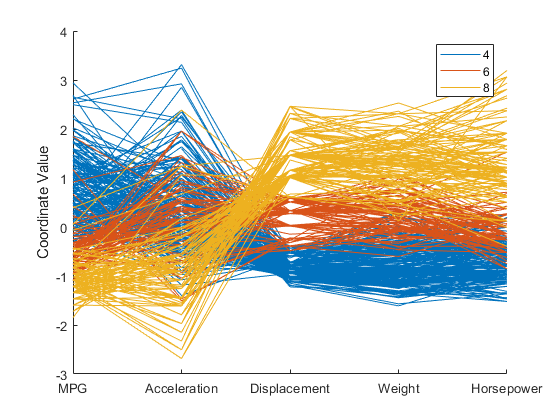
L’image ci-dessus représente la visualisation des features de plusieurs voitures. Le code couleur adopté indique le nombre de cylindres de chaque voiture.
Sur l’axe X on a 5 features (MPG, Acceleration, Displacement, Weight, Horsepower). Sur l’ordonnée (Y), on a les valeurs. Chaque ligne représente une observation de dimension 6 ( les 5 dimensions des features et la 6ème étant la valeur sur l’ordonnée).
Visuellement, on remarque que les voitures à 8 cylindres (lignes jaunes) ont une accélération faible mais un grand nombre de chevaux (Horsepower).
A noter que l’ordre de grandeur des features peut- être très différent. Dans ce cas, avant d’utiliser les parallel Coordinates, il faut penser à faire du feature Scaling.
Merci pour cet article,
et le ebook aussi, très intéressant pour découvrir le monde du data scientist.
Cordialement
Merci Florent pour ton commentaire 🙂
Article super intéressant, je ne conaissait pas les graphique à bulle et à coordonées parallèle, ça va m’être bien utile !
J’en profit pour remercier le travail fait pour tout les articles de ce site en général, chapeau
Merci William pour ton commentaire et ravi de vous avoir comme lecteur du site 🙂
Bonjour
merci pour ce site trés riche et bien présenté
merci, j’ai plus de 15 ans dans le developpement Oracle, mais je change de cap là, je me reconvertis en datasciance et ML
Ravi de pouvoir trouver des experts comme vous aussi généreux pour partager vos connaissances
merci